Attention ! Beaucoup d’informations, beaucoup de captures d’écran et surtout, beaucoup de valeur ajoutée !
Bonjour à tous ! Aujourd’hui, nous allons plonger dans l’univers fascinant de Screaming Frog SEO Spider (ou Screaming Frog,
Seofrog, SEO Screaming Frog, SF, le « crawler », le « spider », ou encore le « parseur » – mettons-nous d’accord sur tous ces synonymes dès maintenant, d’accord ?).
Alors, qu’est-ce que Screaming Frog SEO Spider ? C’est un outil indispensable pour analyser la structure interne des sites web. Grâce à ce programme, vous pouvez rapidement identifier les problèmes techniques d’un site et rédiger un cahier des charges précis pour leur résolution. Mais pour détecter ces problèmes, il faut d’abord bien configurer le crawler, n’est-ce pas ? C’est exactement ce que nous allons explorer ensemble dans cet article.
Remarque de l’auteure :
Lors de la rédaction de cet article, je me suis appuyée sur des ressources complémentaires, notamment le guide officiel fourni par les développeurs. Si cela vous intéresse, vous pouvez le consulter ici : Guide utilisateur officiel de Screaming Frog SEO Spider.
Pour commencer, explorons le menu principal de Seo Spider Screaming Frog afin de comprendre où se trouvent les différentes fonctionnalités et à quoi elles servent.
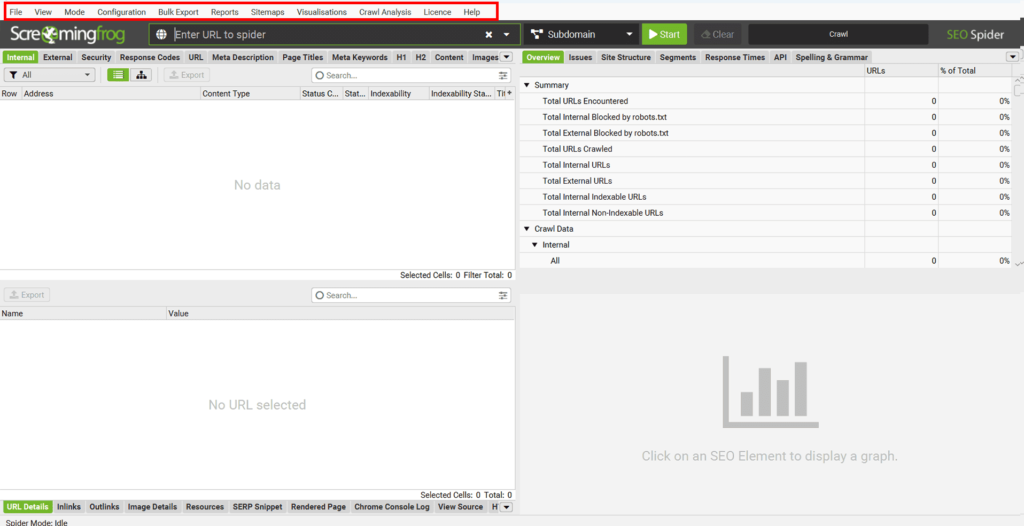
« File » : Gestion des fichiers du programme.
Comme son nom l’indique, cette section concerne la gestion des fichiers dans Screaming Frog. Vous pouvez y charger, enregistrer ou planifier des projets et configurations.
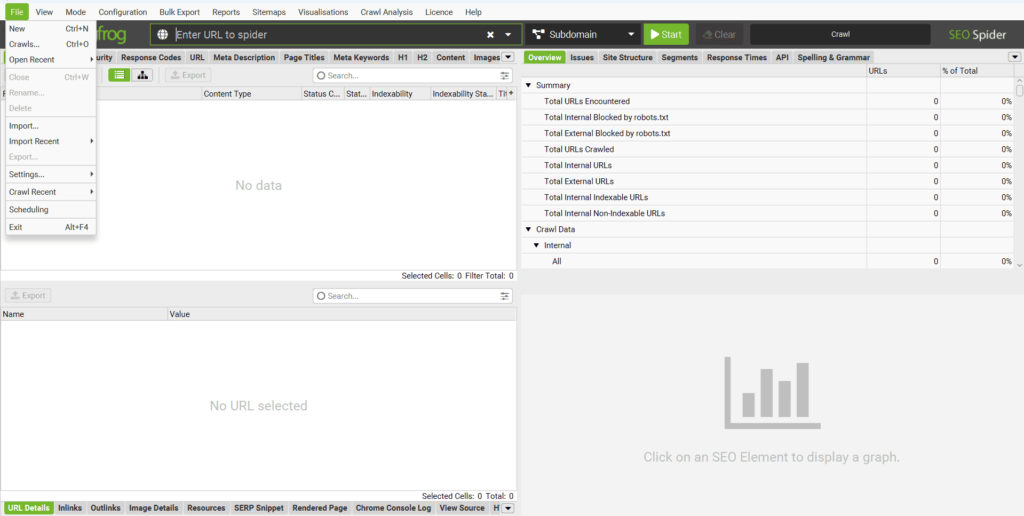
Voici une description des principales options disponibles :
- « Open » (Ouvrir) : Ouvrir un fichier contenant une analyse précédemment réalisée.
- « Open Recent » (Fichiers récents) : Accéder rapidement au dernier projet d’analyse enregistré sous forme de fichier.
- « Save » (Enregistrer) : Enregistrer les données de l’analyse en cours pour une utilisation future.
- « Configuration » : Charger ou enregistrer des configurations spécifiques d’analyse, par exemple pour inclure des paramètres avancés. (Nous verrons plus tard comment configurer ces options en détail.)
- « Crawl Recent » (Analyses récentes) : Relancer l’analyse d’un site déjà examiné récemment dans le programme.
- « Scheduling » (Planification) : Planifier des tâches d’analyse à effectuer ultérieurement. Une fonction intéressante que, je l’avoue, je n’ai jamais utilisée… un peu honteuse.
- « Exit » (Quitter) : Quitter le programme (rien de bien sorcier ici, c’est évident).
« Configuration » : Un des menus les plus importants.
C’est ici que tout se joue ! La section « Configuration » est l’une des plus intéressantes (et cruciales) du menu principal. C’est ici que l’on paramètre les réglages de l’analyse. Préparez-vous, car les choses vont devenir un peu complexes : de nombreux paramètres sont divisés en sous-menus, certains d’entre eux possèdent même des fenêtres avec plusieurs onglets remplis d’options… Bref, accrochez-vous, il y aura beaucoup d’informations à digérer.
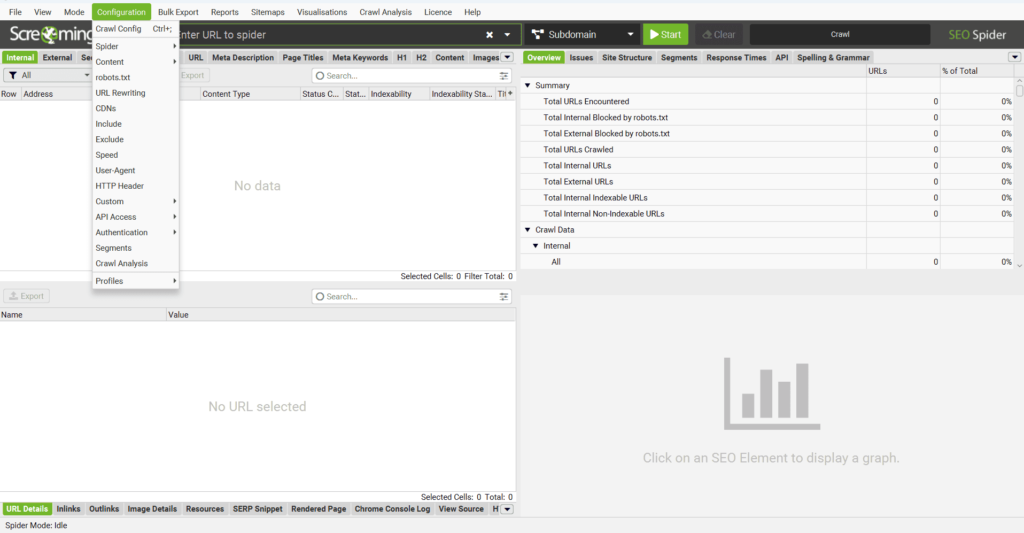
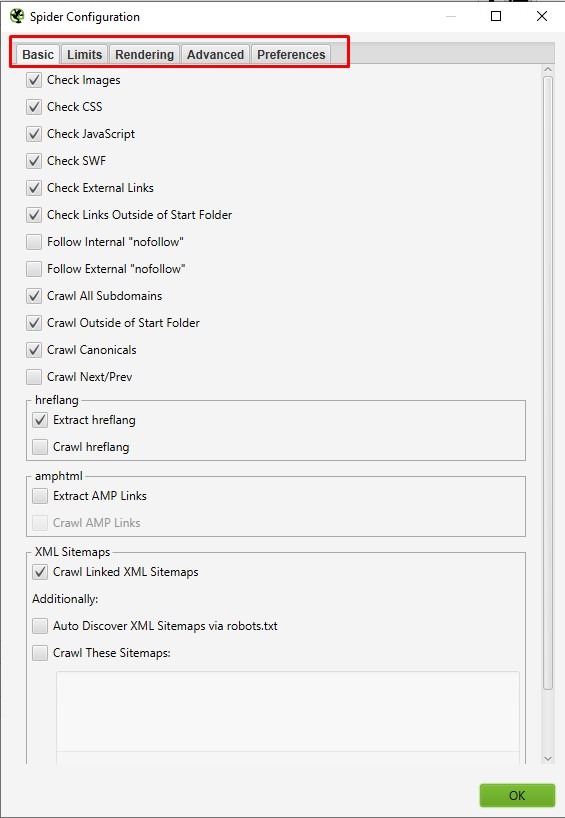
« Configuration » – « Spider ».
La configuration du module « Spider » dans Screaming Frog est le cœur de l’analyse SEO. C’est ici que vous ajustez les paramètres pour personnaliser le crawl en fonction de vos objectifs.
Onglet « Basic »
Passons maintenant à l’onglet « Basic » de la configuration de Screaming Frog. C’est ici que vous définissez précisément ce que vous souhaitez analyser. Voici un aperçu des options disponibles :
- « Check Images » (Vérifier les images) : Inclure l’analyse des images dans le rapport.
- « Check CSS » (Vérifier les CSS) : Inclure l’analyse des fichiers CSS (feuilles de style).
- « Check JavaScript » (Vérifier le JavaScript) : Inclure l’analyse des fichiers JavaScript.
- « Check SWF » (Vérifier le Flash) : Inclure l’analyse des animations Flash.
- « Check External Links » (Vérifier les liens externes) : Ajouter l’analyse des liens externes (vers d’autres sites) dans le rapport.
- « Check Links Outside of Start Folder » (Vérifier les liens hors dossier initial) : Analyser les liens en dehors du dossier de départ. Cela signifie que le rapport portera sur le dossier de départ, tout en tenant compte des liens de l’ensemble du site.
- « Follow internal “nofollow” » (Suivre les “nofollow” internes) : Analyser les liens internes marqués par l’attribut “nofollow”.
- « Follow external “nofollow” » (Suivre les “nofollow” externes) : Analyser les liens externes marqués par l’attribut “nofollow”.
- « Crawl All Subdomains » (Analyser tous les sous-domaines) : Analyser tous les sous-domaines liés au domaine principal.
- « Crawl Outside of Start Folder » (Analyser hors du dossier initial) : Permet d’analyser tout le site, mais en commençant par le dossier spécifié.
- « Crawl Canonicals » (Analyser les canoniques) : Inclure l’attribut
rel="canonical"dans le rapport lors de l’analyse des pages. - « Crawl Next/Prev » (Analyser Next/Prev) : Inclure les attributs
rel="next"etrel="prev"dans le rapport pour les pages paginées. - « Extract hreflang / Crawl hreflang » (Extraire/analyser hreflang) : Considérer l’attribut linguistique
hreflanglors de l’analyse, afficher les codes de langue et de région des pages, et générer un rapport spécifique. - « Extract AMP Links / Crawl AMP Links » (Extraire/analyser les liens AMP) : Extraire dans le rapport les liens avec l’attribut AMP (détection des versions adaptées des pages).
- « Crawl Linked XML Sitemaps » (Analyser les sitemaps XML liés) : Analyser les fichiers sitemap XML liés. Vous pouvez me laisser les détecter automatiquement via le fichier
robots.txt(« Auto Discover XML Sitemaps via robots.txt ») ou spécifier un chemin manuel (« Crawl These Sitemaps »).
Alors, compliqué ? Rassurez-vous, avec un peu de pratique, ces paramètres deviendront intuitifs, et vous saurez rapidement lesquels utiliser en fonction de vos besoins. Une petite pause ? Maintenant, continuons… cela ne deviendra pas plus simple !
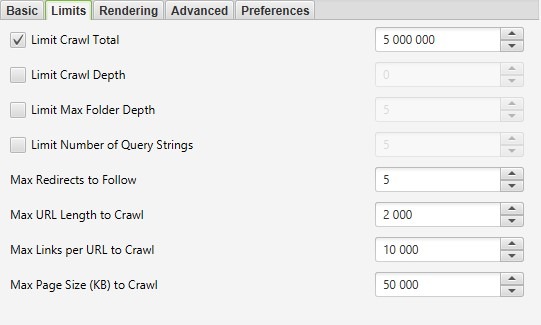
« Configuration » – Onglet « Limits ».
Dans l’onglet « Limits », vous pouvez configurer les restrictions de l’analyse pour optimiser les performances et éviter une surcharge inutile. Voici les principaux paramètres :
- « Limit Crawl Total » (Limite totale d’analyse) : Définir le nombre total de pages à analyser pour un projet.
- « Limit Crawl Depth » (Limite de profondeur d’analyse) : Spécifier la profondeur maximale de l’analyse, c’est-à-dire jusqu’à quel niveau l’analyseur doit explorer le site.
- « Limit Max Folder Depth » (Limite de profondeur des dossiers) : Contrôler la profondeur de l’analyse en fonction des niveaux de dossiers.
- « Limit Number of Query Strings » (Limite du nombre de paramètres) : Un paramètre un peu complexe… En termes simples, il limite le nombre de pages avec des paramètres de requête. Par exemple, sur une page statique avec plusieurs filtres, les combinaisons peuvent générer une infinité de pages dynamiques inutiles. Ce réglage permet de limiter ces pages pour éviter un allongement excessif de l’analyse, souvent peu utile. Exemple :
site.fr/?query1&query2&query3&queryN+1. - « Max Redirects to Follow » (Nombre maximum de redirections) : Définir le nombre maximum de redirections que l’analyseur peut suivre depuis une URL.
- « Max URL Length to Crawl » (Longueur maximale d’URL) : Fixer la longueur maximale des URL à analyser (en caractères).
- « Max Links per URL to Crawl » (Nombre maximum de liens par URL) : Spécifier le nombre maximal de liens présents sur une page que l’analyseur doit suivre.
- « Max Page Size (KB) to Crawl » (Taille maximale de page) : Indiquer la taille maximale d’une page (en kilooctets) que l’analyseur doit analyser.
« Configuration » – Onglet « Rendering ».
Dans l’onglet « Rendering », vous pouvez configurer les paramètres liés au rendu des pages. Trois options sont disponibles :
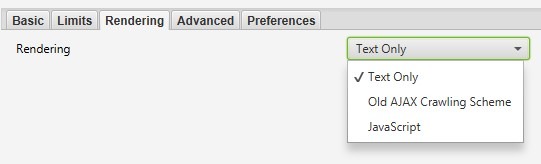
- « Text Only » (Texte uniquement) : L’analyseur examine uniquement le texte présent sur la page.
- « Old AJAX Crawling Scheme » (Ancien schéma d’analyse AJAX) : Effectue l’analyse en utilisant une méthode obsolète d’exploration basée sur AJAX.
- « JavaScript » : Prend en compte les scripts JavaScript lors du rendu des pages. Seule l’option « JavaScript » propose des réglages détaillés pour affiner le rendu.
Lorsque vous sélectionnez l’option « JavaScript », plusieurs paramètres détaillés deviennent disponibles :
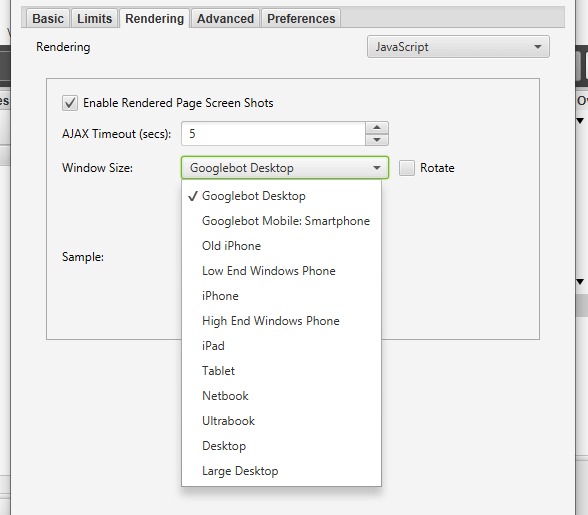
- « Enable Rendered Page Screen Shots » (Activer les captures d’écran des pages rendues) : Permet à Screaming Frog de capturer des captures d’écran des pages analysées. Ces captures sont enregistrées dans un dossier sur votre ordinateur.
- « AJAX Timeout (secs) » (Délai d’expiration AJAX) : Définir la durée limite (en secondes) pendant laquelle SEO Spider autorise l’exécution des scripts JavaScript avant de vérifier si la page est entièrement chargée.
- « Window Size » (Taille de la fenêtre) : Permet de sélectionner la taille de la fenêtre utilisée pour le rendu. Plusieurs options sont disponibles (voir l’exemple dans la capture d’écran).
- « Sample » (Aperçu) : Affiche un aperçu de la fenêtre en fonction de la taille sélectionnée dans « Window Size ».
- « Checkbox Rotate » (Case à cocher Rotation) : Active l’option de rotation pour voir l’aperçu (« Sample ») dans un mode pivoté, selon l’orientation de la fenêtre.
« Configuration » – Onglet « Advanced ».
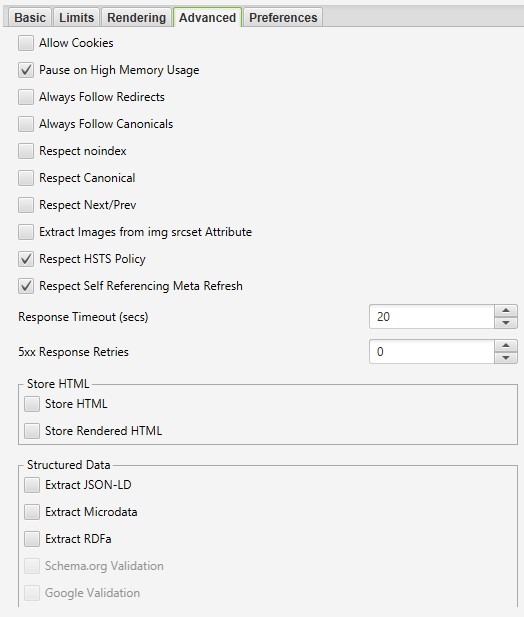
Dans l’onglet « Advanced », vous trouverez des réglages supplémentaires pour personnaliser davantage l’analyse effectuée par Screaming Frog. Voici une explication des principales options :
-
- « Allow Cookies » (Autoriser les cookies) : Permet de prendre en compte les cookies, comme le ferait un bot de moteur de recherche.
- « Pause on High Memory Usage » (Pause si utilisation mémoire élevée) : Met en pause l’analyse si elle consomme trop de mémoire vive.
- « Always Follow Redirects » (Toujours suivre les redirections) : Autorise l’analyseur à suivre les redirections jusqu’à la page finale, quel que soit le code de réponse (200, 4xx, 5xx, etc.), à l’exception des 3xx.
- « Always Follow Canonicals » (Toujours suivre les canoniques) : L’analyseur suit les attributs
rel="canonical"jusqu’à la page finale. Utile pour les sites ayant des problèmes de configuration de canoniques. - « Respect Noindex » (Respecter le noindex) : Les pages marquées avec l’attribut
noindexne sont pas incluses dans le rapport. - « Respect Canonical » (Respecter le canonical) : Tient compte des attributs
rel="canonical"dans le rapport final, ce qui permet d’exclure les doublons générés par des pages dynamiques. - « Respect Next/Prev » (Respecter Next/Prev) : Considère les attributs
rel="next"etrel="prev"pour les pages paginées, ce qui permet d’éviter les doublons dans les métadonnées du rapport. - « Extract Images from img srcset Attribute » (Extraire les images de l’attribut srcset) : Extrait les images définies dans l’attribut
srcsetdes balises<img>. Cet attribut est utilisé pour adapter les images en fonction des tailles ou orientations d’écran. - « Respect HSTS Policy » (Respecter la politique HSTS) : Lorsque cette option est activée, Screaming Frog effectue toutes les futures requêtes en HTTPS, même si le lien initial utilise HTTP. Si désactivée, l’analyseur affiche le code d’état original de la redirection (par exemple, un 301 permanent).
- « Respect Self Referencing Meta Refresh » (Respecter l’auto-rafraîchissement) : Prend en compte les redirections automatiques vers la même URL via le méta-tag
Refresh. - « Response Timeout » (Délai de réponse) : Temps d’attente pour obtenir une réponse d’une page avant que l’analyseur ne passe à l’URL suivante. Ajustez cette valeur pour les sites plus lents.
- « 5xx Response Retries » (Tentatives pour erreurs 5xx) : Nombre de tentatives pour accéder aux pages renvoyant un code serveur 5xx.
Options de sauvegarde :
- « Store HTML » (Stocker le HTML) : Sauvegarde le code HTML statique de chaque URL analysée, avant l’exécution du JavaScript.
- « Store Rendered HTML » (Stocker le HTML rendu) : Sauvegarde le code HTML rendu après l’exécution du JavaScript, permettant de visualiser le DOM final.
Extraction des données structurées :
-
- « Extract JSON-LD » (Extraire JSON-LD) : Extrait les données structurées au format JSON-LD. Vous pouvez activer des options supplémentaires, telles que la validation avec « Schema.org » ou « Google Validation ».
- « Extract Microdata » (Extraire les microdonnées) : Extrait les données structurées au format Microdata, avec les mêmes options de validation que pour JSON-LD.
- « Extract RDFa » (Extraire RDFa) : Extrait les données structurées au format RDFa, également avec des options de validation.
« Configuration » – Onglet « Preferences ».
L’onglet « Preferences », ou “préférences”, vous permet de définir vos critères idéaux pour certains éléments analysés, comme les titres, les descriptions, les URL, les balises H1 et H2, ainsi que les attributs alt et la taille des images. Si les éléments analysés ne correspondent pas à vos préférences, Screaming Frog vous le signalera sous forme d’avertissements. Ces réglages ne sont pas indispensables et peuvent être personnalisés ou laissés par défaut.
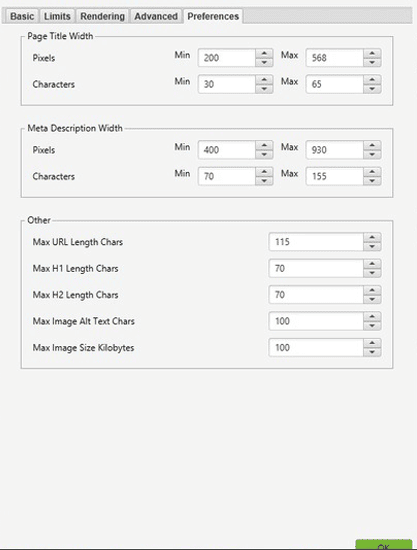
Paramètres disponibles :
- « Page Title Width » (Largeur du titre de page) : Largeur optimale des titres de page. Vous pouvez définir des valeurs minimales et maximales en pixels ou en nombre de caractères.
- « Meta Description Width » (Largeur de la méta-description) : Largeur optimale des descriptions de page. Comme pour les titres, les valeurs minimales et maximales peuvent être définies en pixels ou en caractères.
- « Other » (Autres) :
- « Max URL Length Chars » (Longueur maximale d’URL) : Longueur maximale souhaitée pour les URL, exprimée en caractères.
- « Max H1 Length Chars » (Longueur maximale H1) : Longueur maximale souhaitée pour les balises H1, en caractères.
- « Max H2 Length Chars » (Longueur maximale H2) : Longueur maximale souhaitée pour les balises H2, en caractères.
- « Max Image Alt Text Chars » (Longueur maximale du texte alternatif) : Longueur maximale souhaitée pour les attributs
altdes images, en caractères. - « Max Image Size Kilobytes » (Taille maximale des images) : Taille maximale des images, exprimée en kilooctets (KB).
Ces paramètres sont entièrement optionnels. Vous pouvez les adapter à vos besoins spécifiques ou ne pas les modifier si cela vous semble superflu. Personnellement, je préfère ne pas y toucher pour éviter des alertes inutiles !
« Configuration » – Section « Robots.txt ».
La section « Robots.txt » permet de configurer les règles que Screaming Frog doit suivre lors de l’analyse d’un site. Ces réglages définissent si les directives robots.txt du site doivent être respectées ou ignorées.
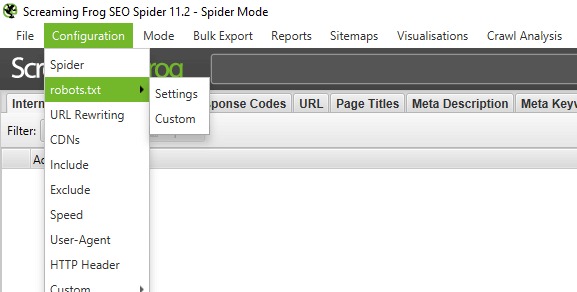
Onglet « Settings ».
- « Respect robots.txt » (Respecter robots.txt) : L’analyseur suit strictement les directives définies dans le fichier
robots.txt. Cela signifie qu’il analysera uniquement les dossiers et fichiers autorisés pour les robots. - « Ignore robots.txt » (Ignorer robots.txt) : Le fichier
robots.txtest totalement ignoré. L’analyseur analysera toutes les pages et ressources du domaine, sans prendre en compte les restrictions. - « Ignore robots.txt but report status » (Ignorer robots.txt mais rapporter le statut) : Le fichier
robots.txtn’est pas pris en compte lors de l’analyse, mais Screaming Frog affichera dans un rapport si les pages sont indexables ou bloquées parrobots.txt.
Options supplémentaires :
- « Show Internal URLs Blocked by robots.txt » (Afficher les URL internes bloquées) : Affiche dans le rapport final les URL internes bloquées par le fichier
robots.txt. - « Show External URLs Blocked by robots.txt » (Afficher les URL externes bloquées) : Affiche dans le rapport final les URL externes bloquées par le fichier
robots.txt.
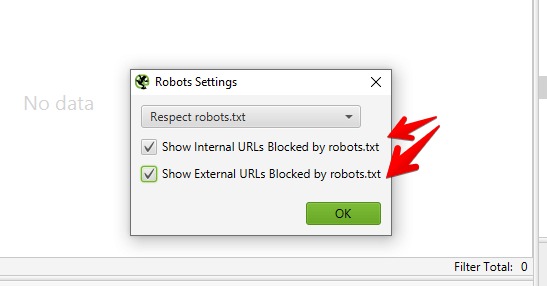
Remarque importante : Ces deux options ne fonctionnent que si l’option « Respect robots.txt » est activée. Ces paramètres permettent d’adapter l’analyse en fonction des besoins spécifiques d’analyse, tout en respectant (ou non) les règles établies par le fichier robots.txt.
Onglet « Custom ».
La fonctionnalité « Custom Robots.txt » de Screaming Frog permet de télécharger, modifier et tester un fichier robots.txt personnalisé pour un site. Les modifications effectuées via cet outil remplacent temporairement la version en ligne du fichier pendant l’analyse, mais elles n’affectent pas directement le fichier robots.txt en ligne.
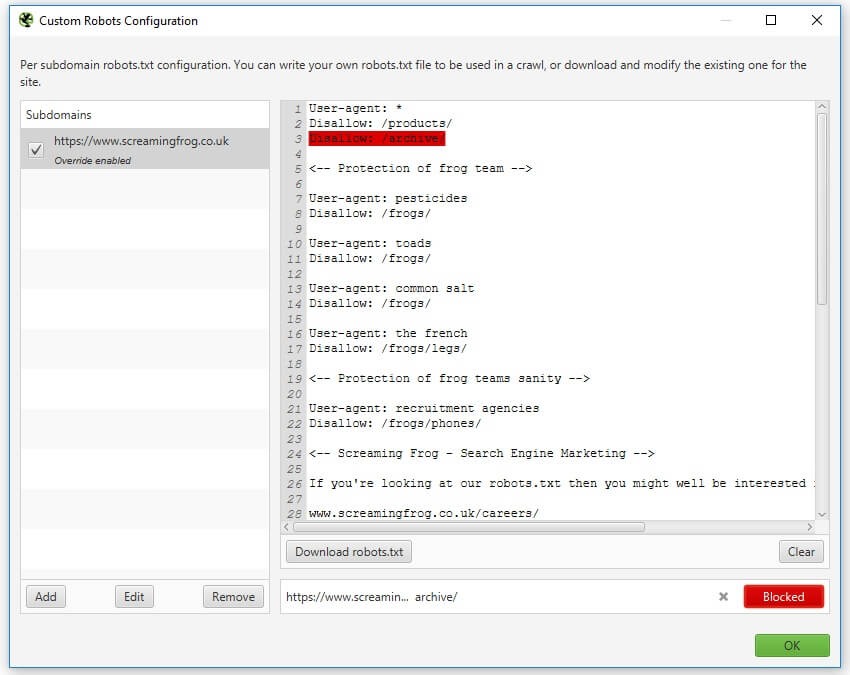
Principales fonctionnalités :
- Modification et gestion par sous-domaines : Vous pouvez ajouter, modifier ou supprimer plusieurs fichiers
robots.txtau niveau des sous-domaines pour simuler des directives spécifiques à tester. Je trouve cette option particulièrement utile pour les gros sites ! - « Override » (Remplacement) des directives existantes : Les directives définies dans le
custom robots.txtremplacent celles du fichier en ligne pour l’analyse. Cela vous permet de tester différents scénarios – super pratique quand on veut faire des essais sans toucher au site en production. - Test des directives et visualisation des URL bloquées : Pendant l’analyse, vous pouvez voir quelles URL sont bloquées ou autorisées en fonction des directives définies. Les URL bloquées apparaissent dans l’onglet « Response Codes » > « Blocked by robots.txt » avec la ligne correspondante du fichier
robots.txt. - « User-Agent » personnalisé : Le fichier
robots.txtpersonnalisé respecte l’agent utilisateur configuré dans les paramètres du SEO Spider.
« Configuration » – Section « URL Rewriting ».
« URL Rewriting » (Réécriture d’URL), c’est la possibilité de modifier des URL directement pendant l’analyse. Utile quand il y a des paramètres ou des expressions régulières qui polluent le rapport final. Par exemple, si des URL dynamiques ou des identifiants inutiles se glissent partout, on peut les nettoyer “à la volée”. Ça évite de se retrouver avec des tonnes de doublons ou des données non pertinentes. Bref, c’est un gain de temps énorme pour analyser des sites complexes ou mal structurés.
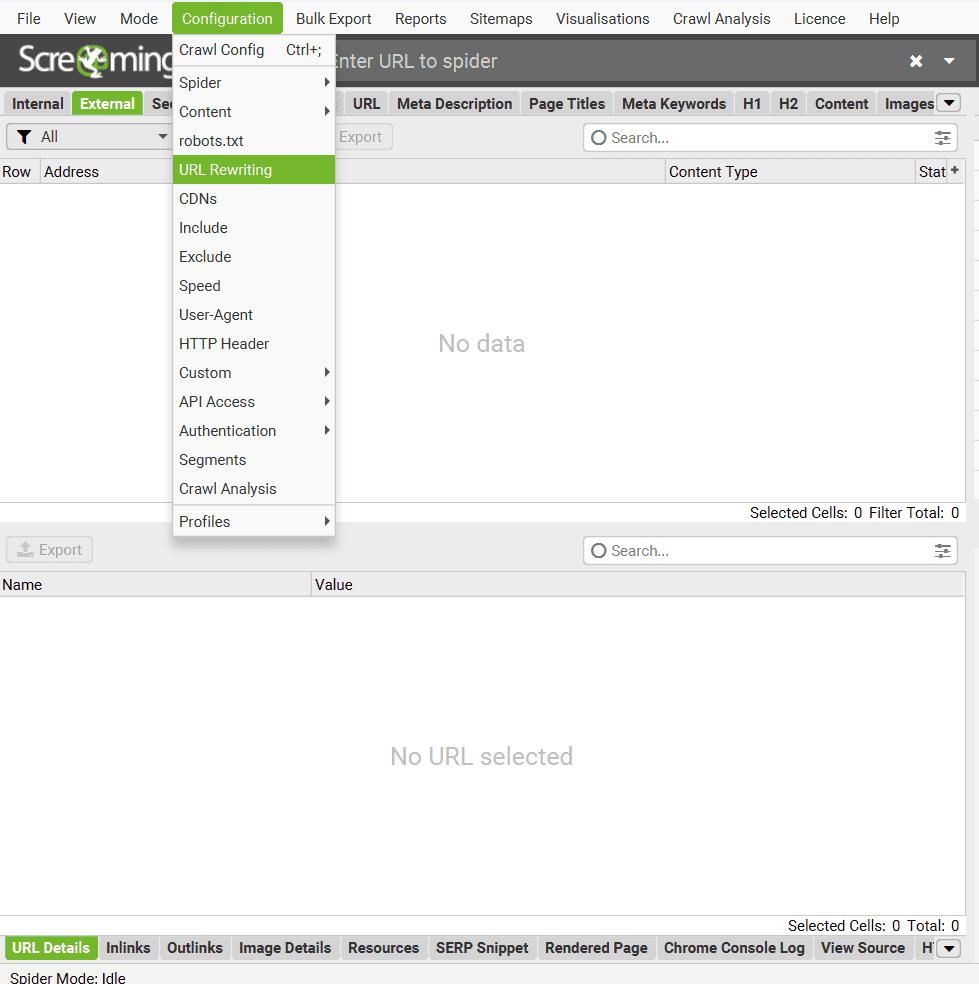
Onglet « Remove Parameters ».
L’onglet « Remove Parameters » (Supprimer les paramètres) permet de supprimer manuellement certains paramètres des URL pendant l’analyse, ou d’exclure tous les paramètres grâce à la case à cocher « Remove all » (Tout supprimer).
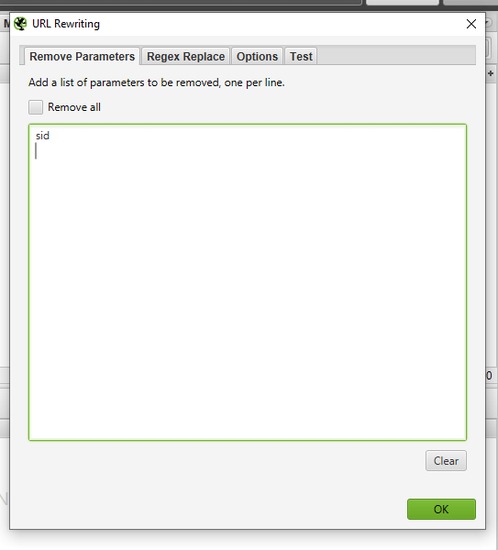
C’est pratique si les URL du site contiennent des éléments inutiles comme des identifiants de session (sid), des paramètres de suivi (utm_source, utm_medium, utm_campaign) ou d’autres variables qui surchargent inutilement le rapport. Grâce à cette option, vous obtenez un rapport plus propre et clair, sans duplication ni données superflues.
Onglet « Regex Replace ».
L’onglet « Regex Replace » (Remplacement par expressions régulières) permet de modifier les URL analysées avec des expressions régulières. C’est super pratique, et je vais vous montrer des exemples concrets !
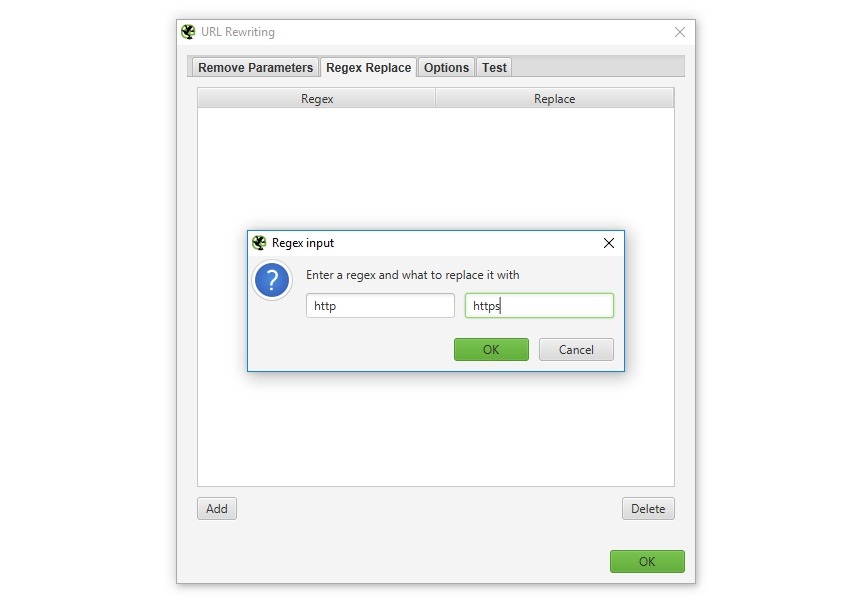
Cas d’utilisation fréquents :
- HTTP vers HTTPS :
- Expression régulière :
http://(.*example.com) - Remplacement :
https://$1 - Note : Idéal pour migrer un site vers HTTPS !
- Expression régulière :
- Modification du domaine :
- Expression régulière :
.com - Remplacement :
.fr - Note : Super utile pour tester différentes versions d’un site
- Expression régulière :
- Nettoyage des paramètres URL :
- Expression régulière :
\?.* - Remplacement : (laisser vide)
- Note : À utiliser avec précaution, préférez l’onglet « Remove Parameters » pour ce cas
- Expression régulière :
- Ajout de paramètres :
- Expression régulière :
$ - Remplacement :
?parametre=valeur - Note : Parfait pour tester des URL avec des paramètres spécifiques
- Expression régulière :
Conseil perso : Utilisez toujours l’onglet “Test” avant de lancer une analyse complète. Ça m’a sauvée plusieurs fois d’erreurs potentielles !
Onglet « Options ».
Si vous vous attendiez à un tas d’options avancées pour affiner le « URL Rewriting », vous risquez d’être déçu(e). Cette section ne propose qu’une seule option : convertir toutes les URL découvertes en minuscules (« Lowercase discovered URLs »).
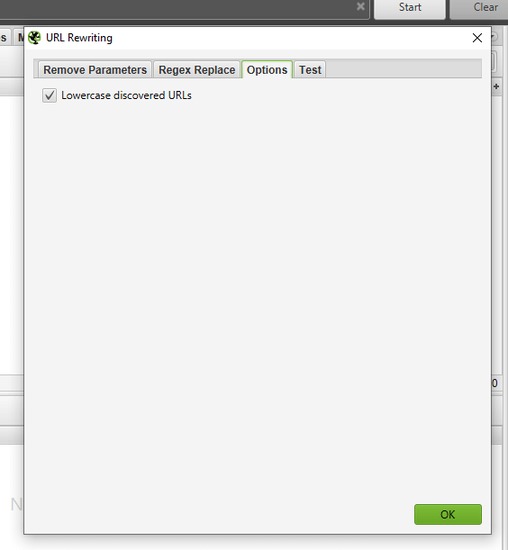
C’est simple : si cette case est cochée, Screaming Frog réécrit automatiquement toutes les URL en minuscules pendant l’analyse. Cela peut être utile pour éviter des doublons si votre site gère différemment les majuscules et minuscules dans les URL.
Pourquoi cette option a-t-elle sa propre section ? Bonne question. Mais c’est tout ce que cette partie fait !
Onglet « Test ».
L’onglet « Test » vous permet de vérifier vos règles de réécriture d’URL avant de lancer l’analyse. Vous pouvez y entrer une URL d’origine et voir immédiatement à quoi elle ressemblera après application des règles définies.
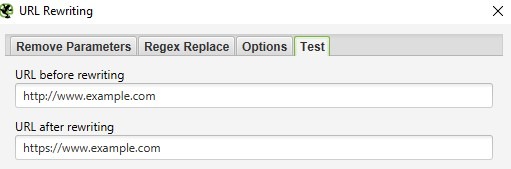
C’est super pratique pour tester vos expressions régulières et vous assurer que tout fonctionne comme prévu. J’utilise toujours cette option avant de me lancer dans une grosse analyse – ça évite les mauvaises surprises ou les erreurs de configuration qui pourraient produire des URL incorrectes dans le rapport final !
« Configuration » – Section « CDNs ».
La section « CDNs » permet d’inclure dans l’analyse des domaines, sous-domaines ou dossiers spécifiques qui seront traités comme des liens internes. En d’autres termes, Screaming Frog considérera ces URL comme faisant partie du site d’origine, même si elles pointent vers d’autres domaines.
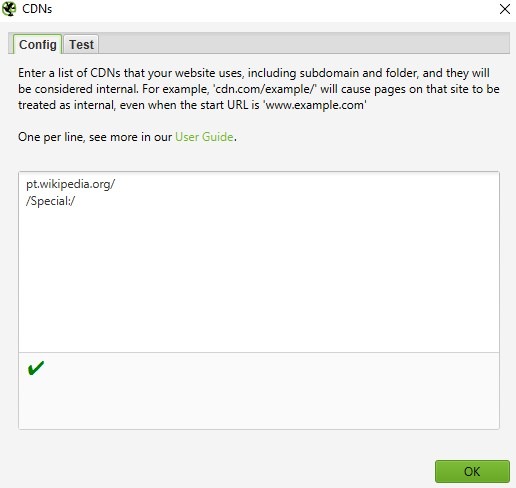
C’est très utile si vous analysez une structure complexe, comme un grand site e-commerce avec des sous-domaines ou des sites régionaux gérés sous la même entité. Vous pouvez également spécifier des chemins particuliers avec des expressions régulières pour ne scanner que certaines sections ou dossiers du site.
Exemple : Si votre site utilise un domaine CDN pour des ressources spécifiques (cdn.monsite.com/images/), vous pouvez l’ajouter ici pour l’inclure dans l’analyse comme s’il faisait partie intégrante du domaine principal. Cela garantit une vue complète et cohérente de votre structure de liens.
L’onglet « Test » permet de vérifier comment les URL seront identifiées (« Internal » ou « External ») en fonction des paramètres utilisés.
« Configuration » – Sections « Include » et « Exclude ».
Les options « Include » (Inclure) et « Exclude » (Exclure) permettent de définir quelles parties d’un site seront incluses ou exclues de l’analyse en utilisant des expressions régulières.
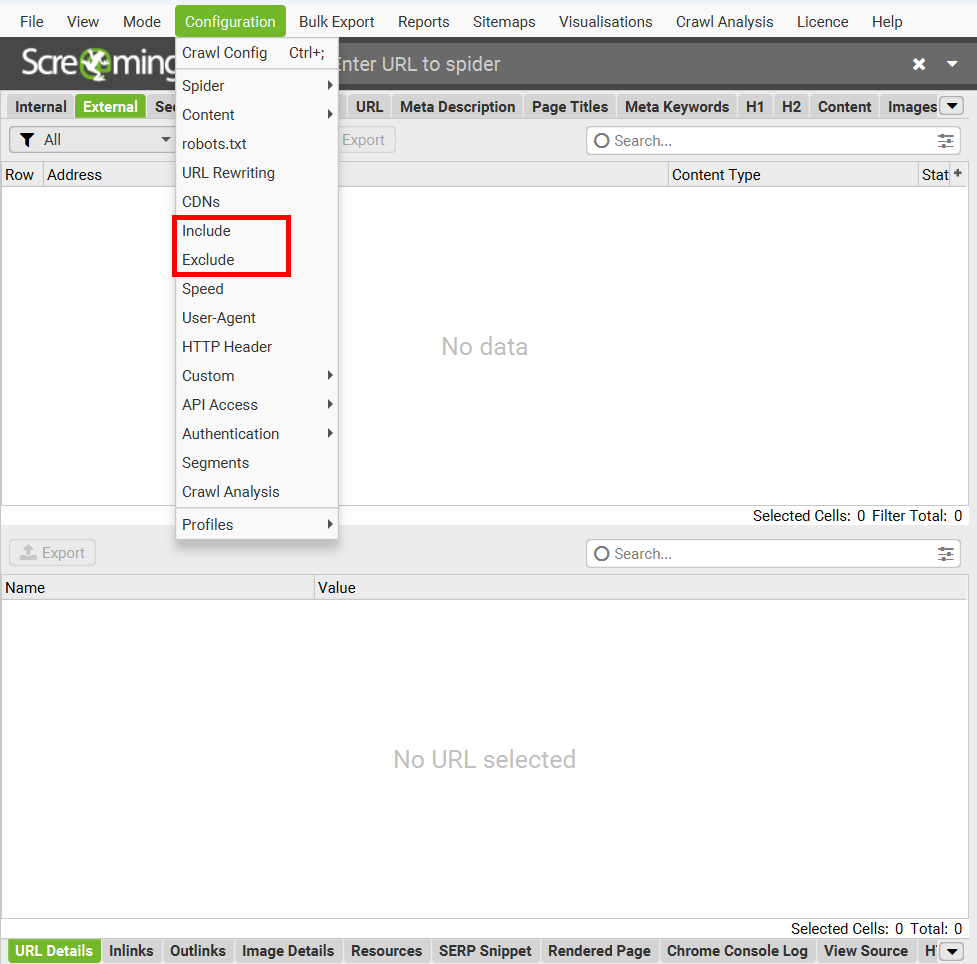
« Include » : Avec cette option, Screaming Frog analysera uniquement les chemins ou dossiers spécifiés. Par exemple, si vous souhaitez analyser uniquement une section comme /blog/, vous pouvez le définir ici.
« Exclude » : Cette option exclut des dossiers ou chemins spécifiques de l’analyse. Le reste du site sera analysé normalement. Par exemple, si vous ne voulez pas analyser /admin/ ou /private/, vous les ajoutez dans cette section.
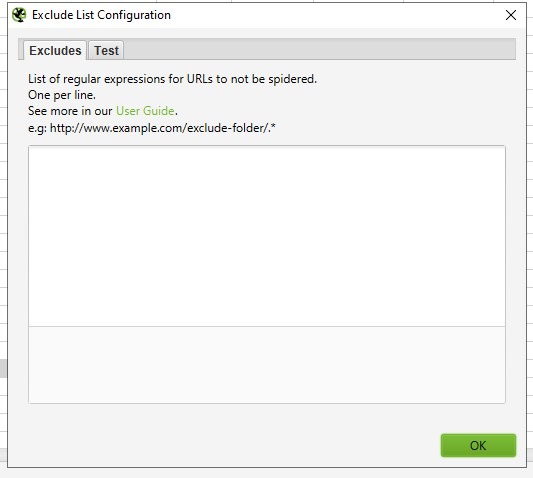
Exemples d’expressions régulières pour « Exclude »
| Catégorie | Expression régulière | Description | Exemple |
|---|---|---|---|
| Paramètres et filtres | .*\?price.* |
Exclut les pages avec le paramètre “price”. | example.com/page?price=100 |
.*\?.* |
Exclut toutes les URL avec des paramètres. | example.com/page?param=value |
|
| Extensions de fichiers | .*jpg$ |
Exclut tous les fichiers .jpg. |
example.com/image.jpg |
| `.*.(png | gif)$` | Exclut les fichiers .png et .gif. |
|
| Mots-clés spécifiques | .*seo.* |
Exclut les URL contenant “seo”. | example.com/seo-tips |
.*admin.* |
Exclut les URL contenant “admin”. | example.com/admin-panel |
|
.*brand.* |
Exclut les URL contenant “brand”. | example.com/brand-page |
|
| Protocoles et domaines | .*https.* |
Exclut les pages en HTTPS. | https://example.com |
http://www.domain.com/.* |
Exclut toutes les pages d’un domaine spécifique. | http://www.domain.com/page |
|
| Formats complexes | .*-[0-9]{6}$ |
Exclut les URL se terminant par 6 chiffres après un tiret. | example.com/product-123456 |
| Cas spéciaux | \Qhttp://www.example.com/test.php?product=special\E |
Exclut une URL complexe contenant des caractères spéciaux. | http://www.example.com/test.php?product=special |
« Configuration » – Section « Speed ».
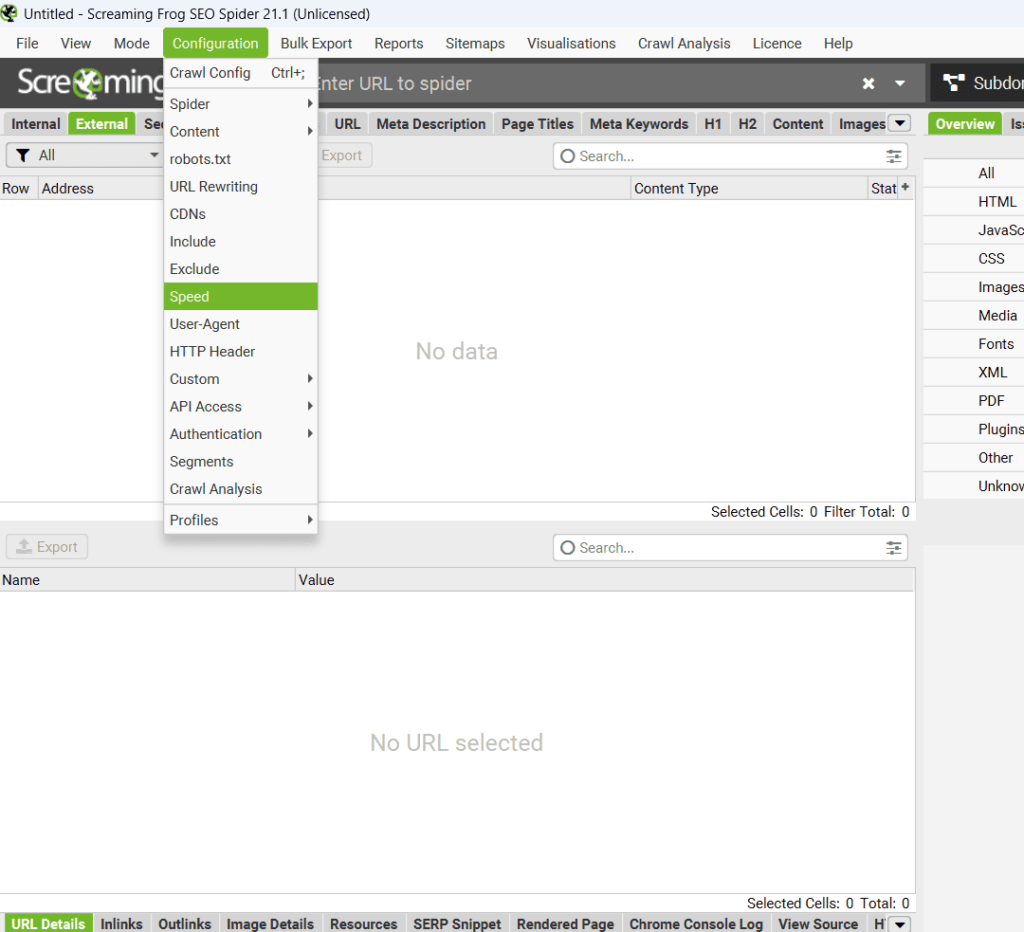
La section « Speed » (Vitesse) permet de régler la vitesse à laquelle Screaming Frog analyse un site. Vous pouvez ajuster deux paramètres principaux :
- « Max Threads » (Nombre de threads) : Le nombre de processus parallèles utilisés pour analyser le site (par défaut : 5).
- « Max URLs per Second » (Nombre d’URLs analysées par seconde) : Cela détermine combien d’URL peuvent être explorées en même temps.
Une vitesse d’analyse élevée peut accélérer le processus, mais augmente également les risques d’être bloqué par le serveur du site. Je vous conseille de trouver un équilibre entre rapidité et prudence pour éviter d’être identifié comme un bot malveillant !
« Configuration » – Section « User-Agent ».
Dans cette section, vous pouvez définir l’identité du bot avec lequel Screaming Frog analysera un site.
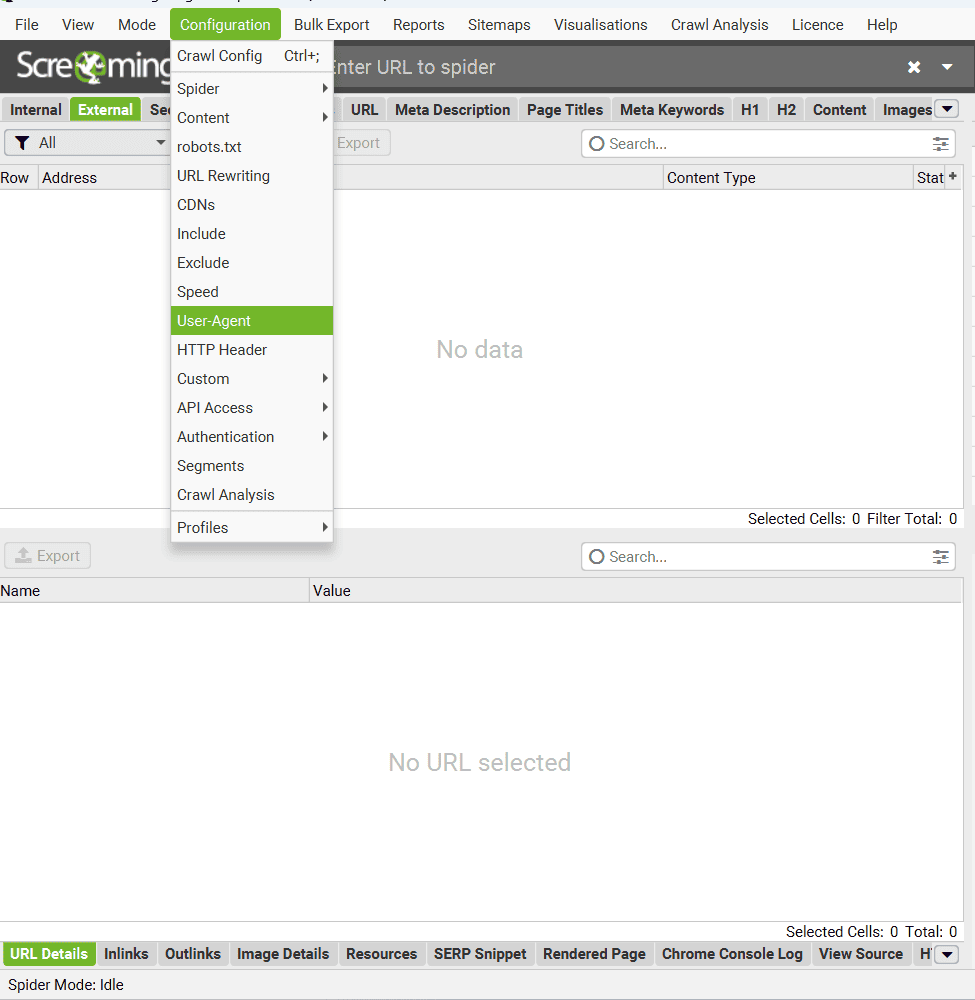
Voici ce qu’il faut savoir :
- « User-Agent » (Agent utilisateur) : Une liste prédéfinie est disponible, incluant des options comme :
- « Googlebot »
- « BingBot »
- « BaiduSpider »
- Et bien d’autres… Vous pouvez également définir un User-Agent personnalisé si nécessaire.
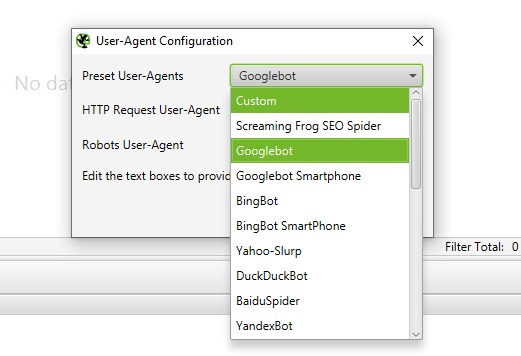
Si jamais vous rencontrez une situation où un site bloque certains bots, par exemple « Googlebot », pas de panique ! Vous pouvez simplement choisir un autre User-Agent pour contourner ces restrictions. C’est super pratique aussi quand vous voulez tester votre site avec « Googlebot Smartphone » – ça vous permet de repérer rapidement les éventuels problèmes d’affichage ou d’optimisation sur mobile.
« Configuration » – Section « HTTP Header ».
La section HTTP Header permet de configurer la manière dont Screaming Frog traite les en-têtes HTTP.
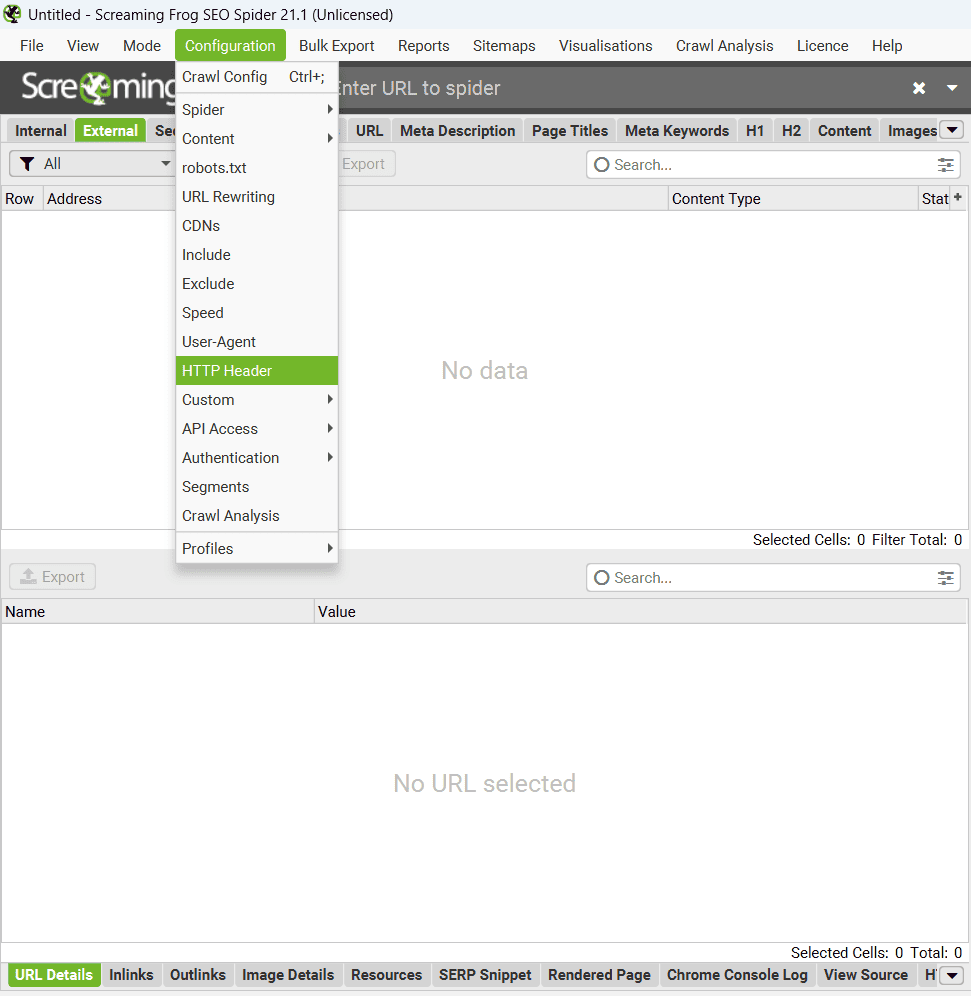
Vous pouvez définir des directives spécifiques comme Accept-Language, Cookie, ou Referer, voire ajouter des noms d’en-têtes uniques selon vos besoins. Bien que très flexible, cette option est surtout utile pour des projets nécessitant un traitement précis des réponses HTTP. Pour une utilisation classique, les paramètres par défaut suffisent généralement.
« Configuration » – Section « Custom ».
Les fonctionnalités avancées de la section « Custom » vous permettent d’optimiser vos audits en mettant en lumière des données précieuses et des informations stratégiques souvent invisibles dans les rapports standards.
« Configuration » – « Custom Search ».
La fonctionnalité « Custom Search » (Recherche personnalisée) agit comme un filtre intelligent pour extraire ou identifier des données spécifiques dans le code source des pages analysées. Elle est particulièrement utile pour repérer des anomalies ou vérifier des configurations précises.
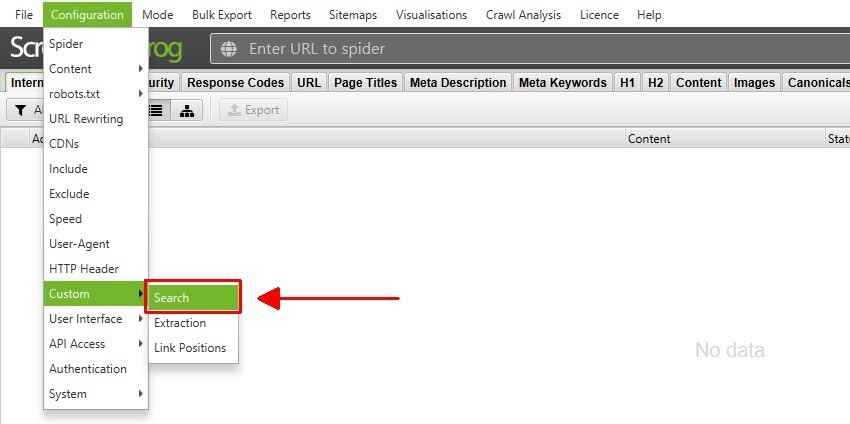
Par exemple, vous pouvez rechercher des balises spécifiques dans le code HTML brut, comme identifier les pages utilisant <bold> au lieu de <strong>. Vous avez aussi la possibilité de trouver des pages sans certains éléments essentiels, comme celles où manque le script de suivi Google Analytics ou Matomo. Le système permet de configurer jusqu’à 100 filtres en combinant texte et expressions régulières pour des recherches très précises.
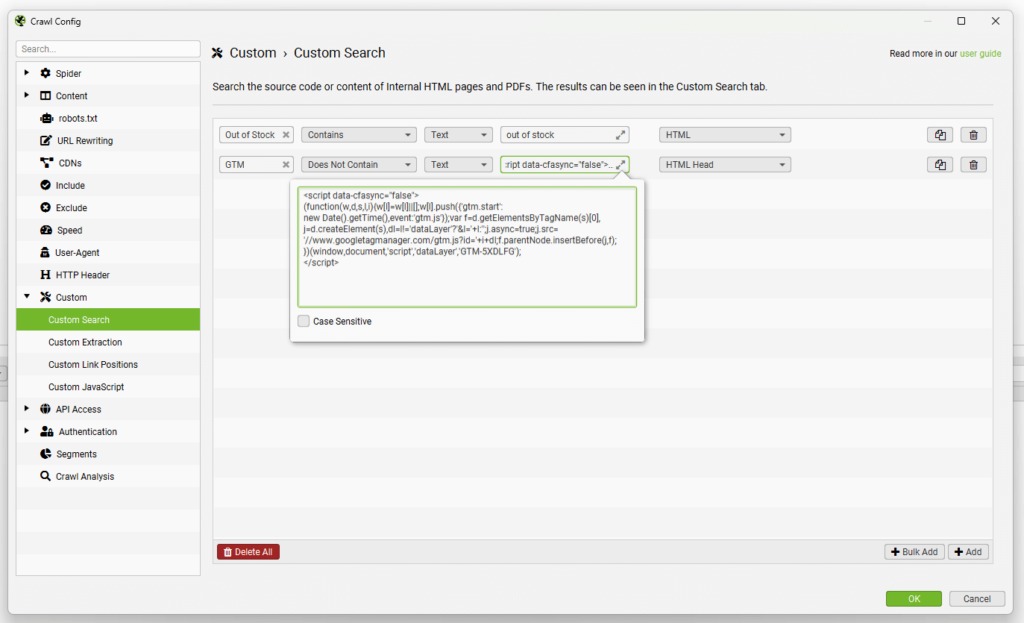
Vous pouvez choisir si votre recherche s’effectue sur le HTML brut ou rendu (via le mode JavaScript), et même sélectionner des zones spécifiques comme le corps de la page ou l’en-tête HTML. J’utilise souvent cette fonction pour mes audits techniques approfondis, c’est vraiment un outil puissant.
« Configuration » – « Custom Extraction ».
La fonctionnalité « Custom Extraction » (Extraction personnalisée) vous permet d’extraire des données spécifiques du code HTML pendant l’analyse. Imaginez que vous voulez récupérer des descriptions de produits, vérifier des balises de suivi ou extraire des données structurées en JSON-LD – c’est exactement à ça que ça sert !
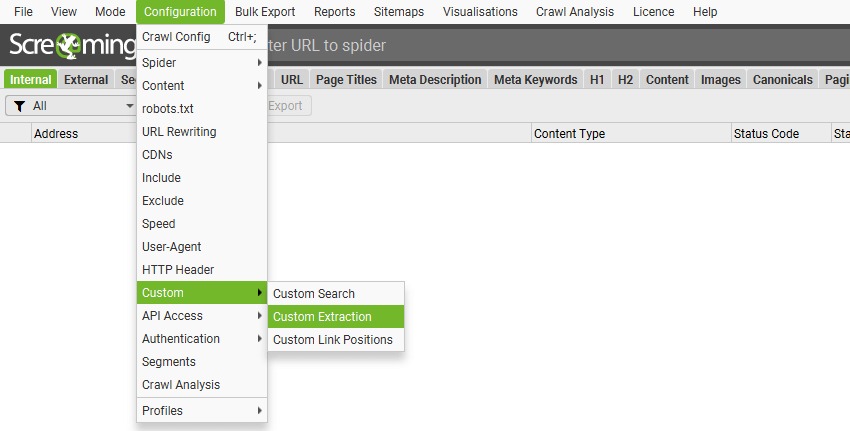
En pratique, vous pouvez extraire tout type de contenu : des balises <meta>, des scripts spécifiques, ou même des éléments personnalisés. Le plus intéressant, c’est que vous pouvez utiliser des expressions régulières pour cibler précisément ce que vous cherchez.
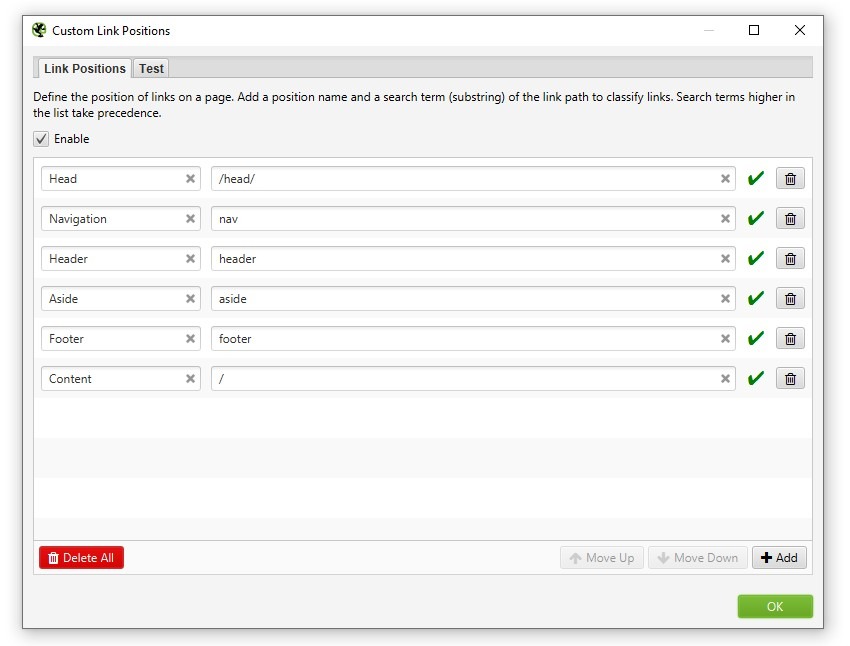
« Configuration » – « Custom Link Positions ».
La fonctionnalité « Custom Link Positions » (Positions personnalisées des liens), elle vous permet de voir où se trouve chaque lien sur vos pages – que ce soit dans le menu principal, le contenu, la barre latérale ou le footer.
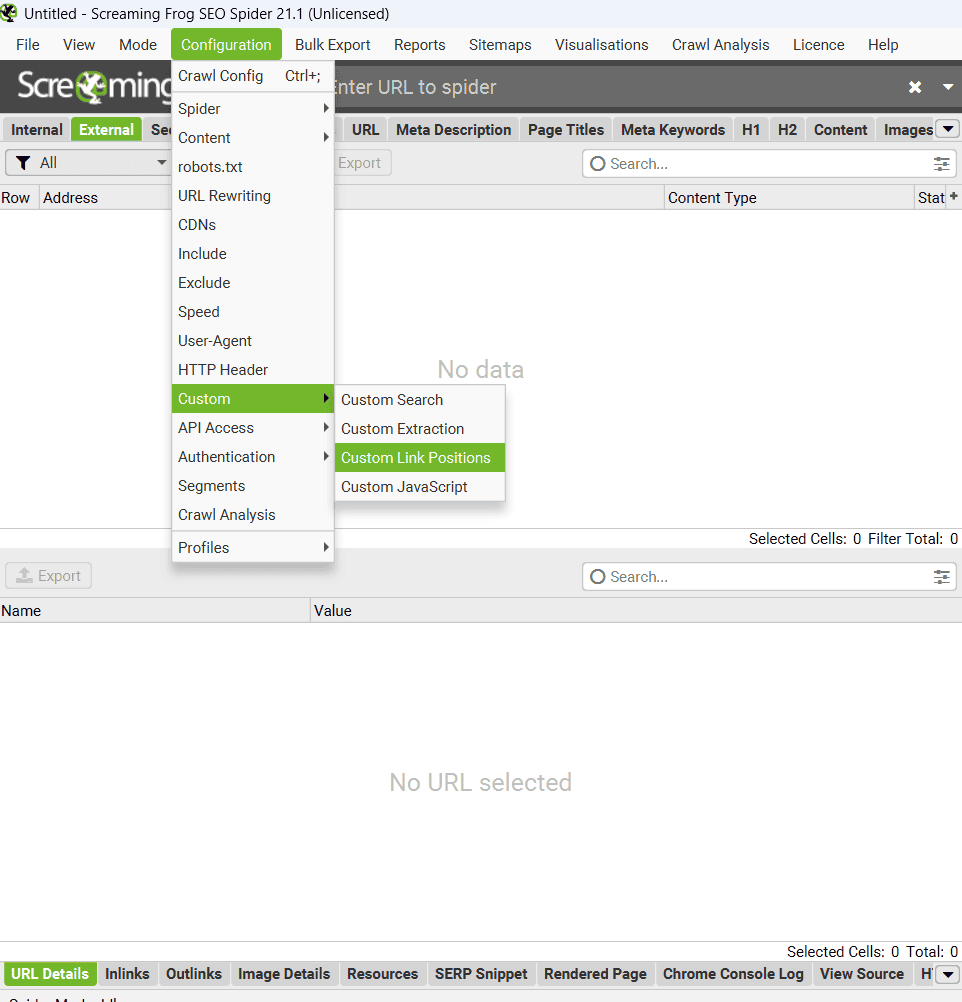
Pour faire simple, l’outil utilise le chemin XPath pour identifier automatiquement où se trouvent vos liens. C’est super utile quand vous voulez vous concentrer uniquement sur les liens dans le contenu principal, sans être parasité par ceux du menu ou du footer. Vous retrouverez toutes ces informations dans les onglets « Inlinks » et « Outlinks ».
« Configuration » – « Custom JavaScript ».
La section « Custom JavaScript » vous permet d’exécuter du code JavaScript personnalisé pendant l’analyse de vos pages (uniquement les URL internes avec un code 200 OK, hors PDF).
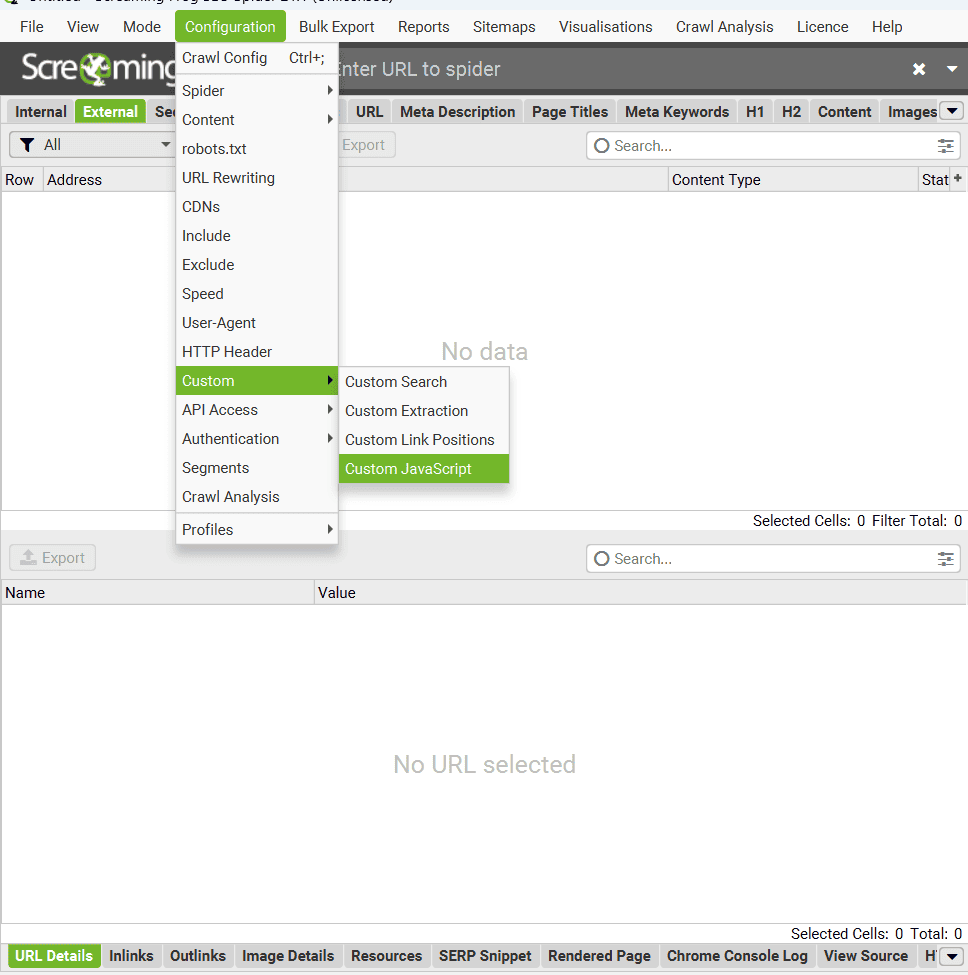
Cette fonction vous permet d’extraire plein d’informations utiles qui ne sont pas disponibles dans l’interface standard de SEO Spider. Vous pouvez même communiquer avec des API comme ChatGPT d’OpenAI ou d’autres modèles de langage, et sauvegarder tout ça directement sur votre ordinateur.
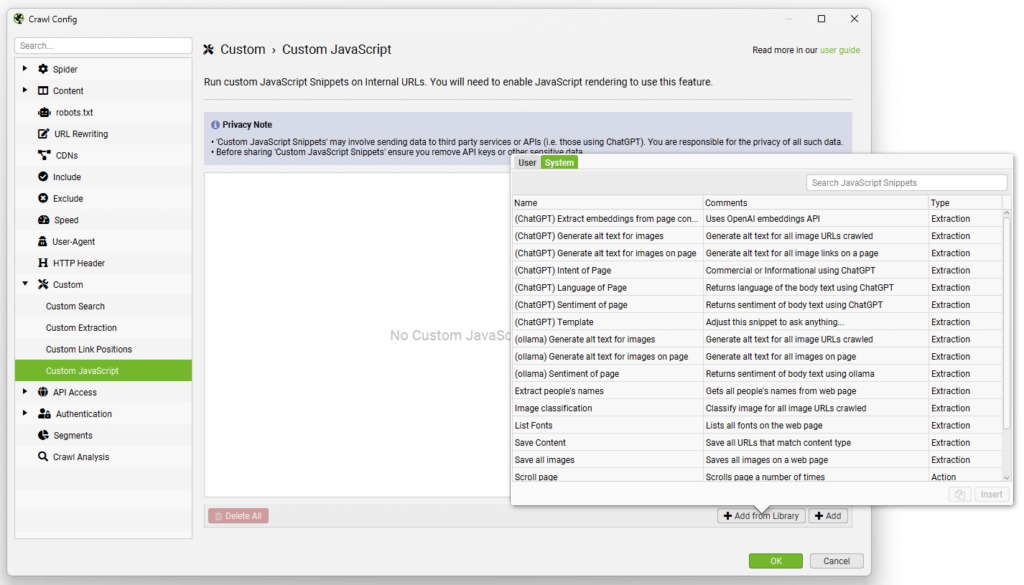

« Configuration » – Google Universal Analytics et Google Analytics 4.
Vous pouvez connecter Screaming Frog directement aux API de Google Universal Analytics et GA4 pour intégrer vos données d’analyse pendant l’audit. C’est super pratique, car vous pouvez voir vos indicateurs de performance en même temps que vous analysez votre site.
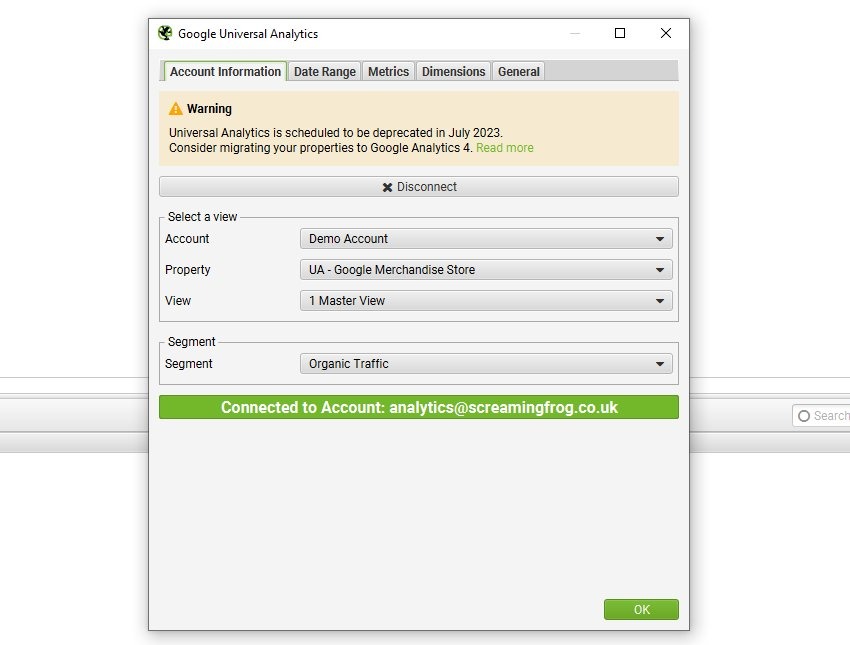
Pour Google Universal Analytics, vous pouvez :
- Choisir le compte, la propriété et la vue qui correspondent à votre site.
- Sélectionner un segment utilisateur spécifique.
- Définir une période pour les données que vous voulez récupérer.
- Importer des métriques comme les sessions, le taux de conversion, les transactions ou même les revenus.
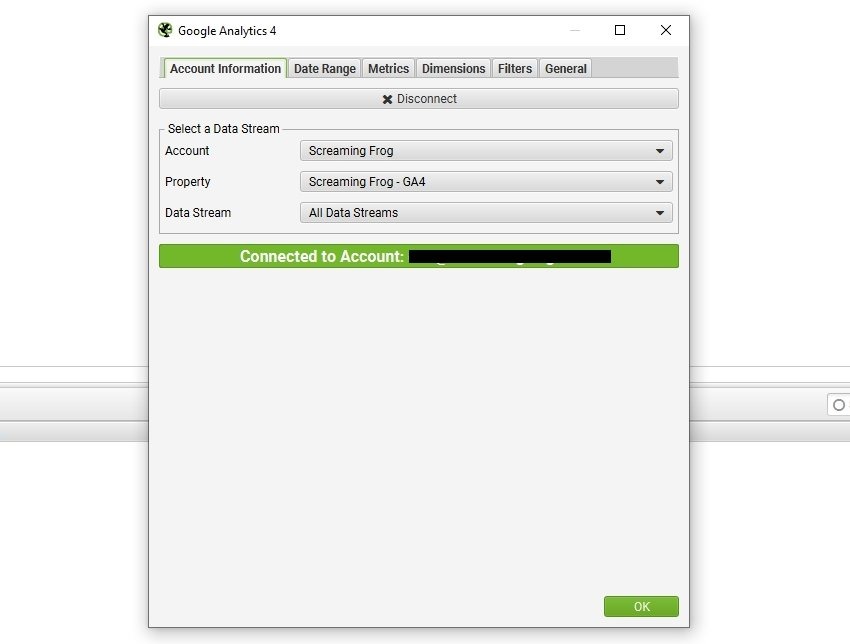
Avec Google Analytics 4 (GA4), c’est tout aussi simple :
- Connectez votre compte et sélectionnez la propriété et le flux de données (Data Stream).
- Récupérez les événements, conversions ou toute autre métrique clé.
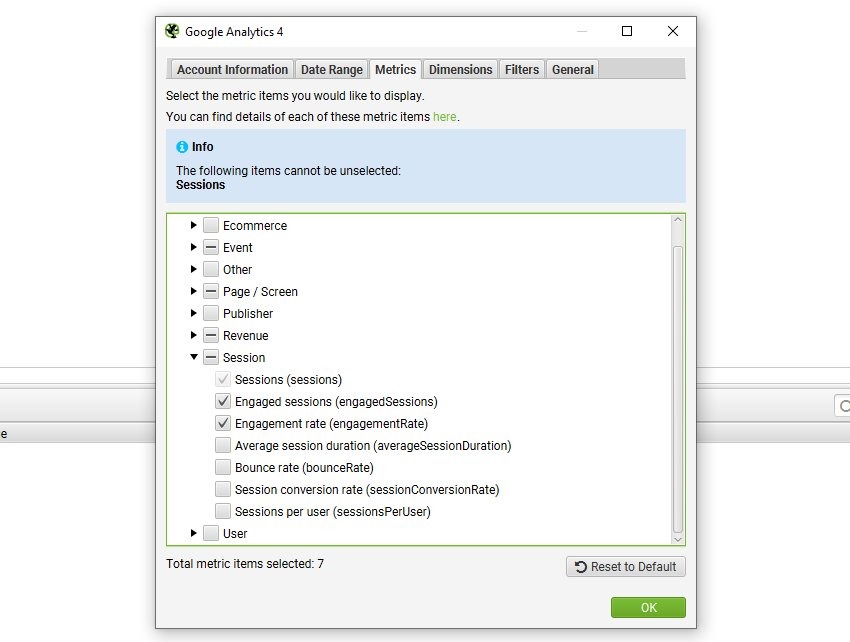
Pendant un audit technique ou de contenu, ces intégrations vous permettent d’analyser vos meilleures pages en termes de trafic ou de revenus tout en repérant celles qui ont besoin d’optimisation. Tout est intégré directement dans Screaming Frog, vous donnant une vision claire et complète des performances de votre site.
« Configuration » – Google Search Console.
Screaming Frog peut se connecter directement à deux API super utiles de Google : « Search Analytics » et « URL Inspection ».
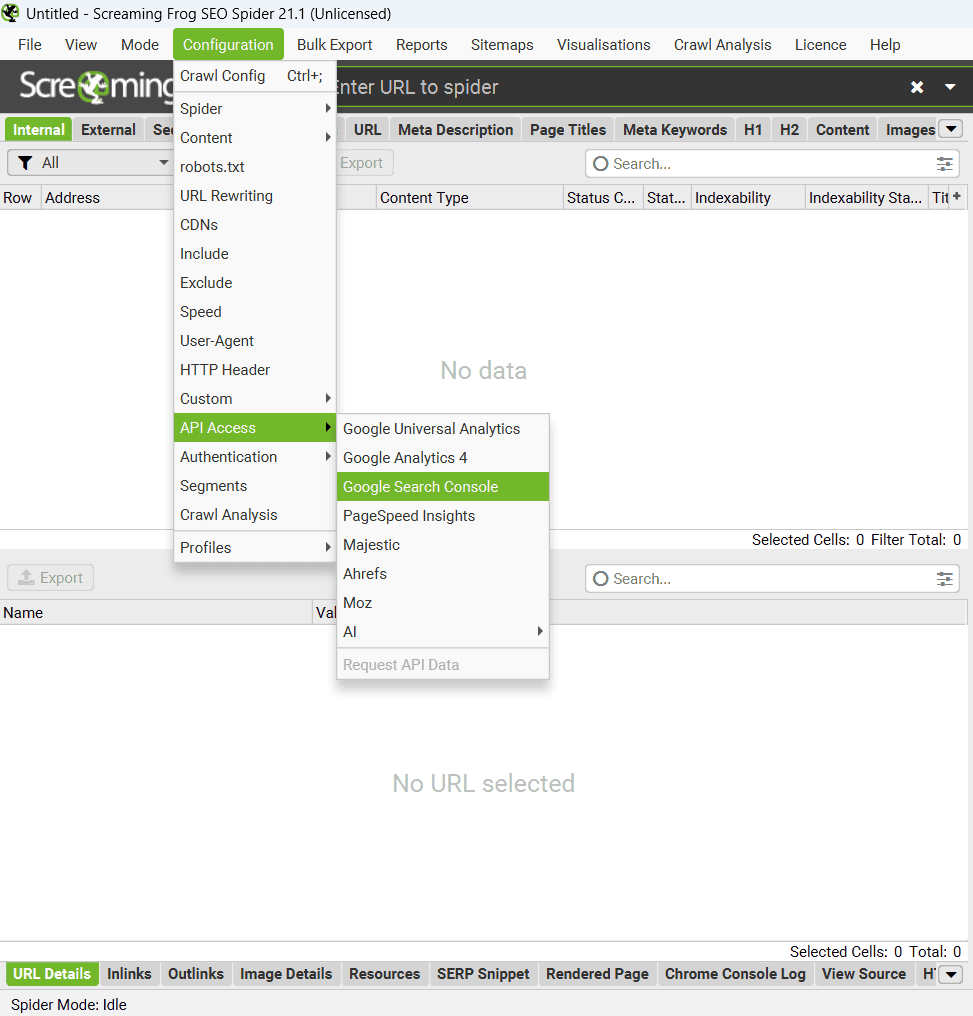
Avec « Search Analytics », vous récupérez tous les indicateurs clés : impressions, clics, CTR et positions moyennes. Pour « URL Inspection », vous pouvez vérifier en un clin d’œil si vos pages sont bien indexées et détecter d’éventuels problèmes.
Le plus intéressant ? Vous pouvez analyser toutes ces données pendant votre audit technique. C’est parfait pour repérer rapidement vos pages performantes et celles qui ont besoin d’optimisation.
« Configuration » – « PageSpeed Insights ».
Screaming Frog peut se connecter à l’API « Google PageSpeed Insights » pour analyser la vitesse de vos pages et l’expérience mobile pendant votre audit. C’est basé sur « Lighthouse », l’outil de Google, qui vous donne aussi accès aux données réelles d’expérience utilisateur (« Core Web Vitals »).
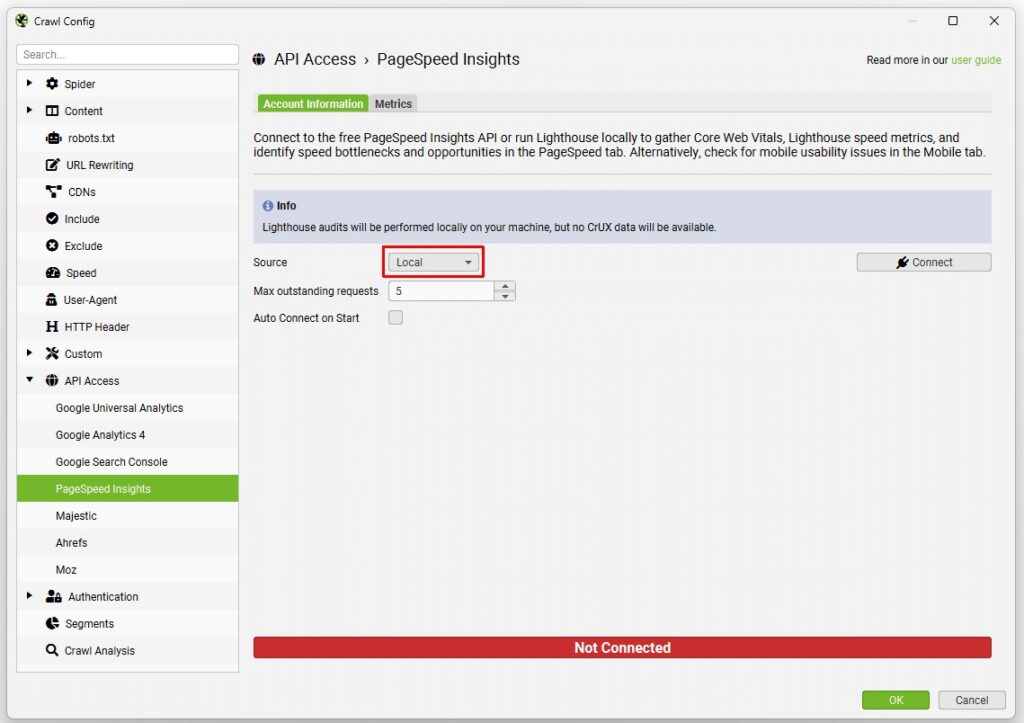
Vous avez deux options d’analyse :
- « Remote » : L’analyse se fait sur les serveurs de Google. Super pratique pour avoir les données « CrUX » (expérience utilisateur réelle) !
- « Local » : L’analyse se fait sur votre machine. Idéal pour les sites avec authentification, et pas de limite de requêtes quotidiennes.
« Configuration » – Intégration avec « Majestic », « Ahrefs » et « Moz ».
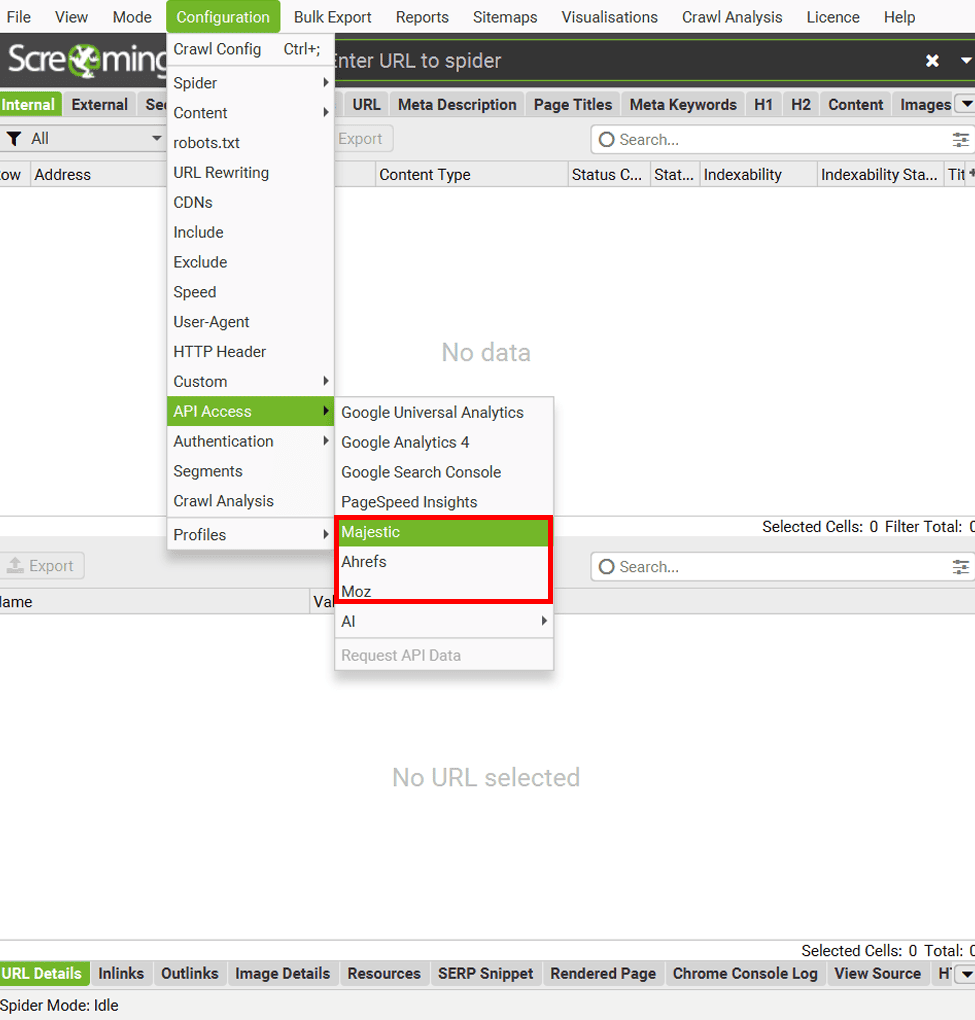
Ces trois outils enrichissent votre analyse avec des données essentielles sur l’autorité de domaine, les backlinks et bien plus encore.
« Majestic » (abonnement payant requis) :
- Données fresh ou historic
- Analyse au niveau URL, sous-domaine ou domaine
- Configuration rapide via « Configuration > API Access > Majestic »
« Ahrefs » (abonnement standard suffit) :
- Version 2 de l’API (pas besoin de plan entreprise)
- Accès via « Configuration > API Access > Ahrefs »
- Nombre de données selon votre abonnement
« Moz » (version gratuite ou payante) :
- API gratuite : données de base
- API payante : plus de métriques, analyse plus rapide
- Configuration via « Configuration > API Access > Moz »
Cliquez sur « Start » pour lancer l’analyse, et les données seront automatiquement récupérées via l’API et visibles dans les onglets « Link Metrics » et « Internal ».
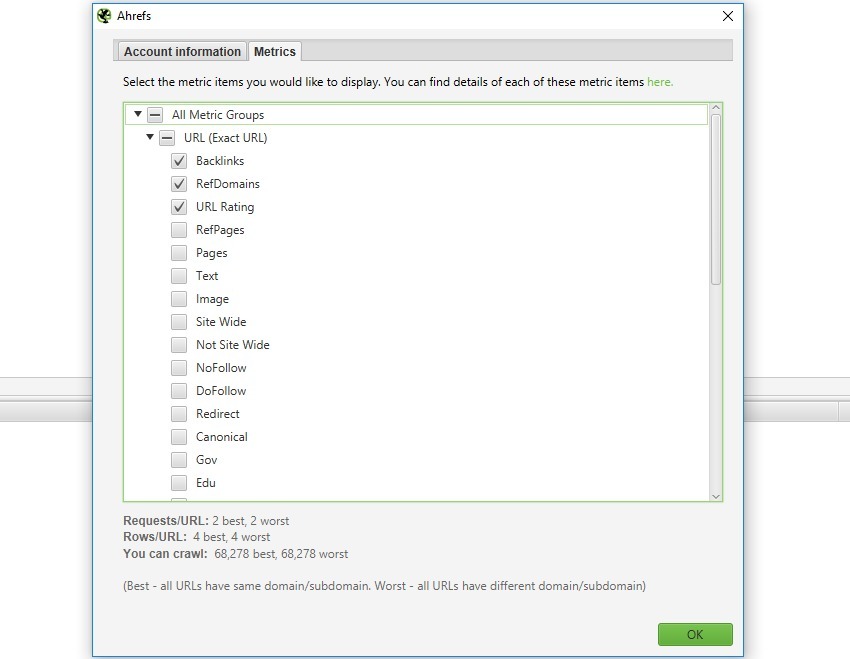
« Configuration » – « AI ».
Screaming Frog propose maintenant une intégration avec trois IA pour analyser automatiquement le contenu de vos pages. L’IA va analyser vos pages pour repérer les problèmes SEO, évaluer la qualité du contenu et vous suggérer des améliorations. C’est comme avoir un assistant SEO qui analyse votre site en permanence.
« OpenAI » (compte payant) : Avec GPT-4, vous pouvez analyser en profondeur le contenu de toutes vos pages d’un coup. C’est parfait pour les gros sites qui nécessitent un audit détaillé. L’IA peut vous dire si votre contenu est pertinent, suggérer des optimisations SEO et même repérer les pages qui ont besoin d’être retravaillées.
« Gemini » : C’est une alternative plus économique à OpenAI, avec une version gratuite très performante. Il est particulièrement doué pour analyser rapidement vos textes et identifier les points d’amélioration.
« Ollama » : Si la confidentialité est importante pour vous, c’est la solution idéale car tout fonctionne en local sur votre machine. Pas de frais mensuels, et vous gardez le contrôle total sur vos données.
Vous pouvez créer vos propres instructions pour l’IA selon vos besoins spécifiques. Par exemple, demandez-lui d’évaluer vos titres ou de suggérer des améliorations pour vos meta descriptions.
« Configuration » – Section « Authentication ».
Vous devez analyser un site qui nécessite une connexion ?
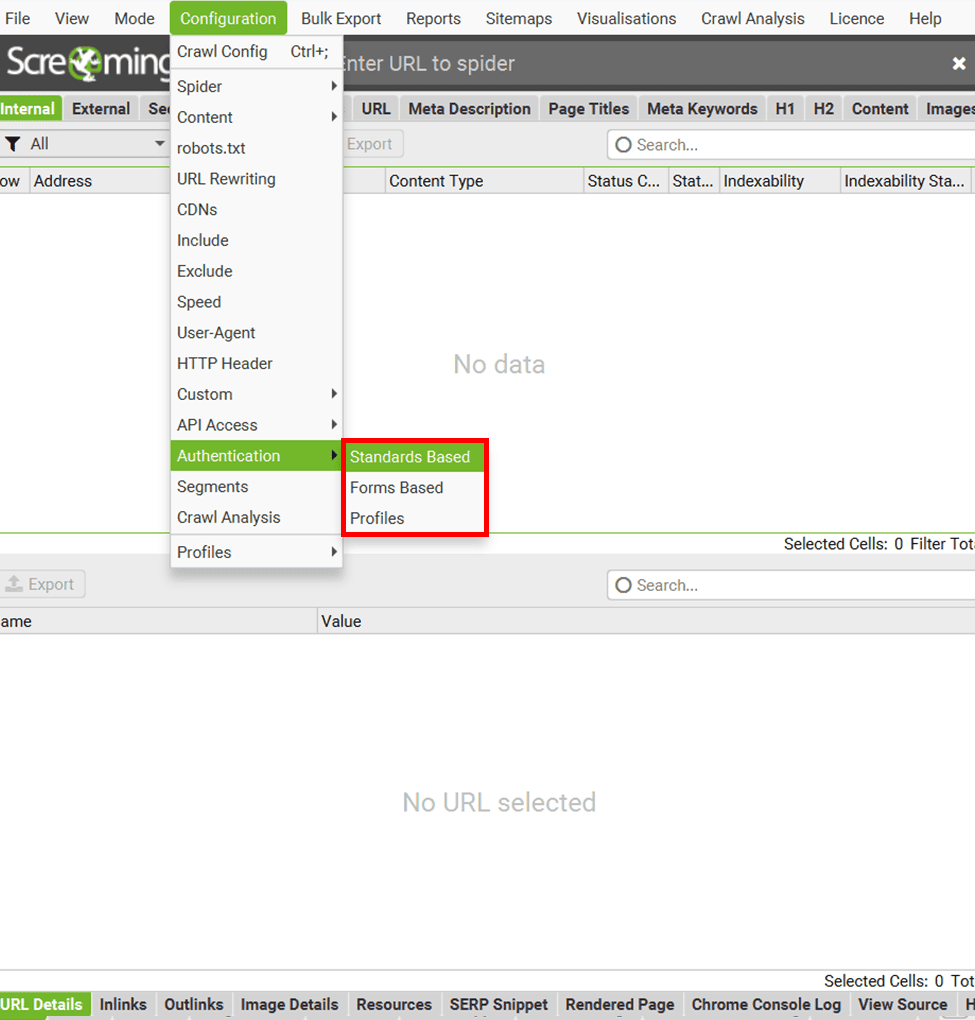
Screaming Frog propose deux solutions simples :
Authentification Standard (gratuit) : C’est pour les sites qui affichent une petite fenêtre pop-up de connexion dans votre navigateur. Super simple à utiliser : entrez l’URL et Screaming Frog vous demandera automatiquement vos identifiants, exactement comme votre navigateur. Vous pouvez aussi enregistrer vos identifiants à l’avance dans « Config > Authentication » pour gagner du temps.
Authentification par Formulaire (version payante) : Pour les sites avec un vrai formulaire de connexion sur la page. Screaming Frog utilise son propre navigateur intégré : allez dans « Config > Authentication > Forms Based », ajoutez l’URL et connectez-vous comme d’habitude.
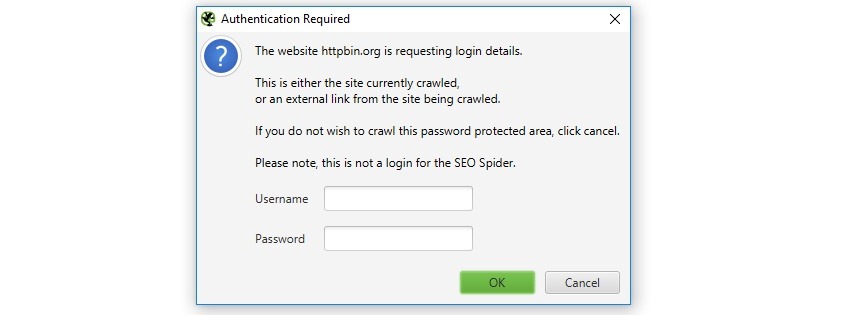
Attention pratique : Soyez prudent avec l’authentification par formulaire ! Comme Screaming Frog clique sur tous les liens, il pourrait accidentellement cliquer sur “déconnexion” ou d’autres boutons sensibles. Je vous conseille de bien vérifier vos paramètres avant de lancer l’analyse.
Vous pouvez sauvegarder vos configurations d’authentification pour les utiliser plus tard avec la planification ou la ligne de commande. Pratique pour les audits réguliers. Exportez simplement votre configuration depuis l’onglet « Profiles ».
« Configuration » – Section « Segments ».
La section « Segments » divise votre site en catégories pour identifier les problèmes spécifiques à chaque section (blog, produits, catégories…).
Cette fonction nécessite d’activer le stockage en base de données dans « File > Settings > Storage Mode ».
La configuration se fait dans « Configuration > Segments », où vous pouvez créer des segments en utilisant les données de crawl, de Google Analytics ou de Search Console. Ces segments sont visualisés par code couleur dans une colonne dédiée, et vous pouvez les modifier à tout moment durant votre analyse.
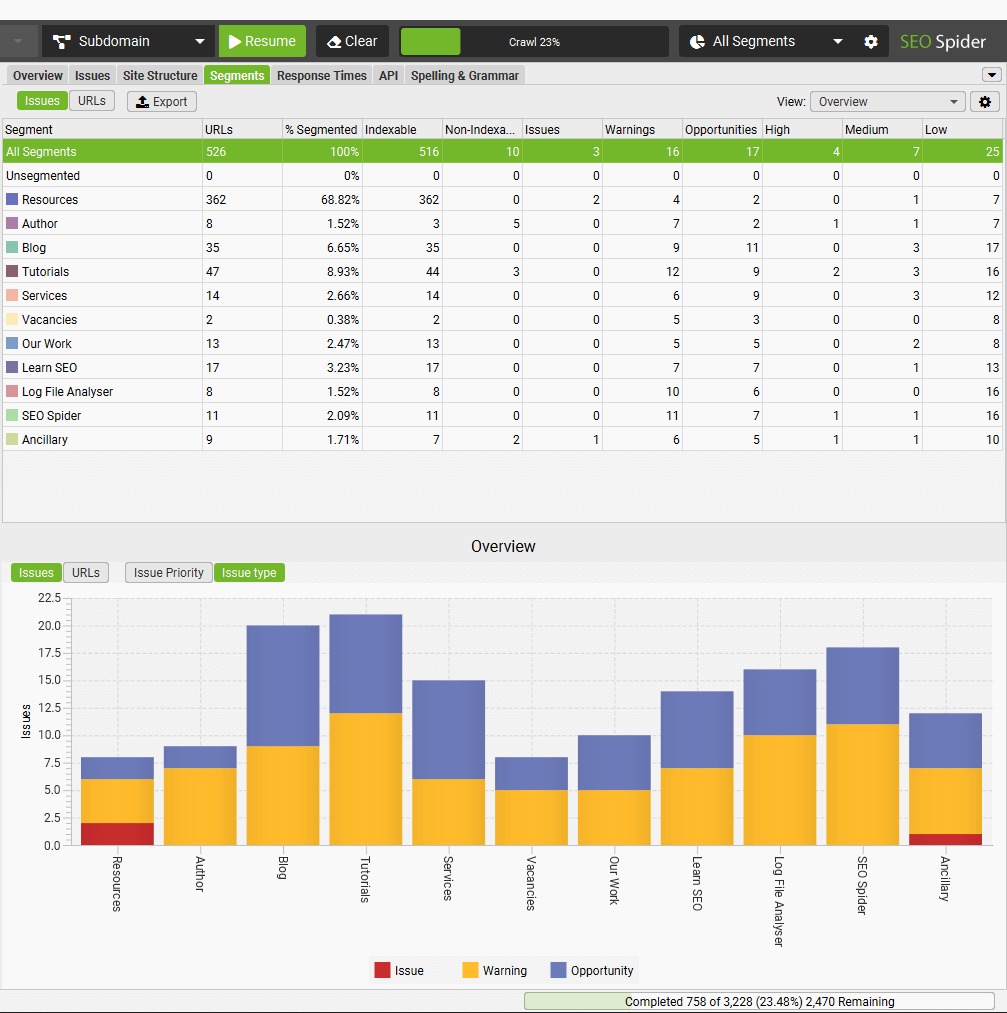
Cette segmentation permet une analyse ciblée par section, la création de sitemaps XML segmentés et la génération de rapports Looker Studio automatisés par segment. Pour les segments qui dépendent d’autres segments, respectez bien l’ordre de priorité dans la configuration.
« Configuration » – Section « Crawl Analysis ».
Cette analyse avancée vous permet de découvrir des insights plus profonds de votre site, comme la valeur de vos liens internes ou les pages orphelines qui ne sont accessibles que via Analytics ou Search Console. C’est particulièrement utile pour optimiser votre structure de liens et repérer les pages oubliées.
Screaming Frog analyse la plupart des données en temps réel pendant le crawl. Cependant, certaines métriques comme le « Link Score » et quelques filtres spécifiques nécessitent une analyse complémentaire à la fin du crawl. Cette analyse peut être lancée automatiquement ou manuellement via « Crawl Analysis > Start ».
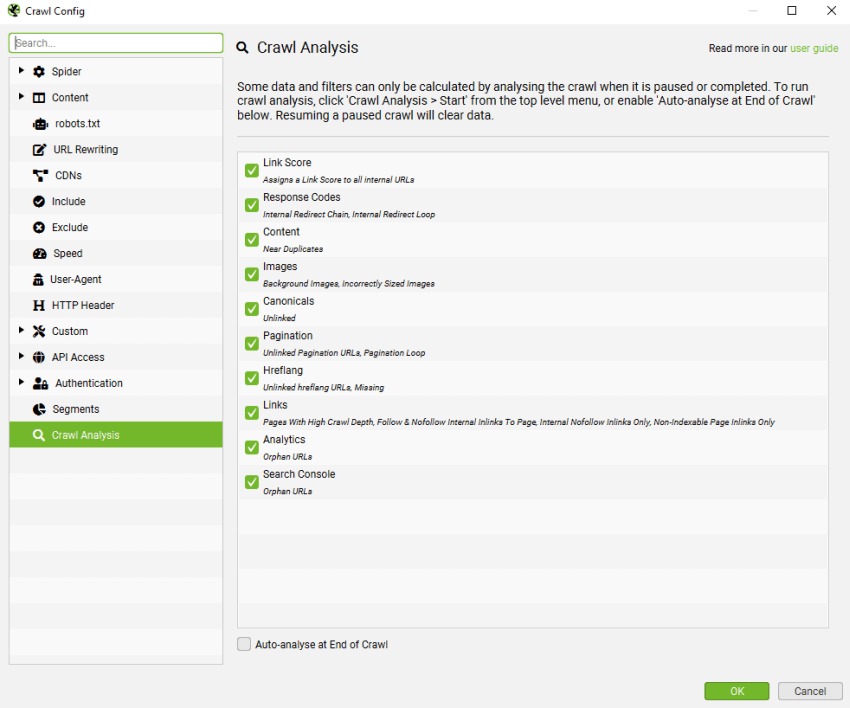
Pour activer l’analyse automatique, cochez « Auto Analyse At End of Crawl » dans la configuration. Pendant l’analyse, une barre de progression s’affiche, mais vous pouvez continuer à utiliser l’outil normalement.
Important pour les données Google : les filtres d’URLs orphelines d’Analytics et Search Console ne seront remplis que si vous avez activé l’option « Crawl New URLs Discovered » dans leurs onglets respectifs. Sinon, ces URLs seront uniquement visibles dans « Reports > Orphan Pages ».
« Mode » – Les différentes façons d’utiliser Screaming Frog.
Screaming Frog propose quatre modes d’analyse différents selon vos besoins. Le mode « Spider » explore l’intégralité de votre site en suivant tous les liens internes – c’est le mode classique pour un audit complet.

Pour une analyse plus ciblée, le mode « List » vous permet d’analyser uniquement certaines URLs de votre choix. C’est particulièrement utile quand vous voulez vérifier des pages spécifiques sans scanner tout le site.
Le mode « SERP » se concentre sur l’analyse des résultats de recherche Google, parfait pour suivre vos positions et collecter des données sur vos concurrents.
Enfin, le mode « Compare » est fait pour comparer deux analyses différentes. Vous pouvez ainsi voir facilement ce qui a changé sur votre site, par exemple après une mise à jour importante.
« Bulk Export » : Exportez facilement vos données d’analyse.
Le menu « Bulk Export » est votre meilleur allié pour extraire rapidement toutes les données collectées par Screaming Frog.
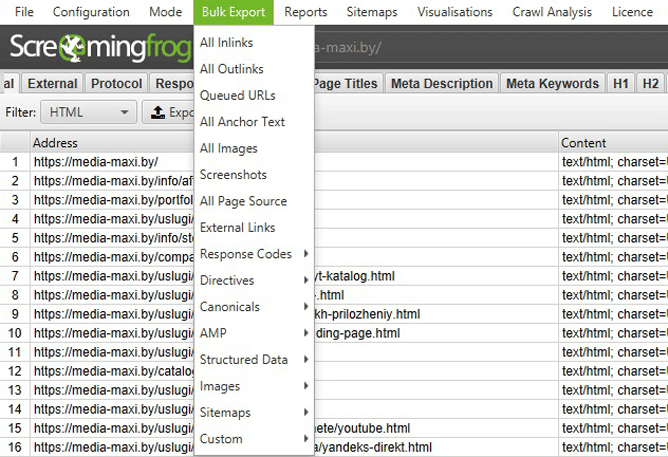
« Bulk Export » – Exportations de données en masse.
Voici les différentes options disponibles :
- « All Inlinks » : Exporte les liens entrants (internes et externes) vers chaque URI analysé.
- « All Outlinks » : Exporte les liens sortants depuis chaque URI analysé.
- « All Anchor Text » : Liste tous les textes d’ancrage des liens.
- « All Images » : Exporte les URLs de toutes les images analysées.
- « Screenshots » : Exporte les captures d’écran des pages.
- « All Page Source » : Extrait le code HTML statique ou rendu (en mode JavaScript).
- « External Links » : Liste tous les liens externes trouvés durant l’analyse.
- « Response Codes » : Regroupe les pages par codes de réponse (200, 3xx, noindex, etc.).
- « Directives » : Exporte les pages avec des directives spécifiques comme
Index,Noindex, ouNofollow. - « Canonicals » : Liste les pages avec ou sans attribut canonique.
- « AMP » : Exporte les pages AMP et leurs éventuelles erreurs.
- « Structured Data » : Liste les pages avec microdonnées ou autres formats de données structurées.
- « Images » : Détecte les images sans balise
altou trop lourdes. - « Sitemaps » : Analyse les pages présentes ou manquantes dans le sitemap.xml.
- « Custom » : Permet des exports basés sur vos filtres personnalisés.
« Reports » : Tous vos rapports d’analyse.
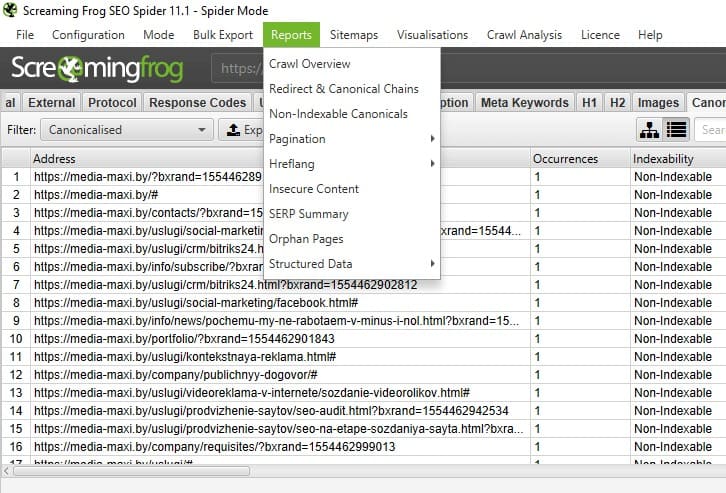
La section « Reports » vous donne accès à des rapports détaillés pour identifier rapidement les problèmes techniques de votre site :
- « Crawl Overview » présente un résumé complet de l’analyse : URLs trouvées, pages bloquées par robots.txt, codes de réponse et types de contenu.
- « Redirect & Canonical Chains » identifie les chaînes de redirections et de balises canoniques, y compris les redirections cycliques.
- « Non-Indexable Canonicals » repère les problèmes avec vos canoniques : pages bloquées par robots.txt, redirections 3xx, erreurs 4xx ou 5xx.
- « Pagination », « Hreflang » et « Insecure Content » détectent respectivement les erreurs de pagination (
rel="next/prev"), les problèmes de versions linguistiques, et les contenus non sécurisés sur les pages HTTPS. - « SERP Summary » analyse vos titres et méta-descriptions avec leurs longueurs en caractères et pixels.
- « Orphan Pages » identifie les pages présentes dans Analytics, Search Console ou Sitemap mais absentes de l’analyse.
- « Structured Data » vérifie la validité de vos données structurées.
« Sitemaps » : Création de votre sitemap XML.
Dans la barre de menu principale, cliquez sur « Sitemaps » pour créer votre sitemap XML. Vous pouvez générer un plan du site pour vos pages web et vos images. Une fois créé, il suffit de le télécharger dans le dossier racine de votre site.
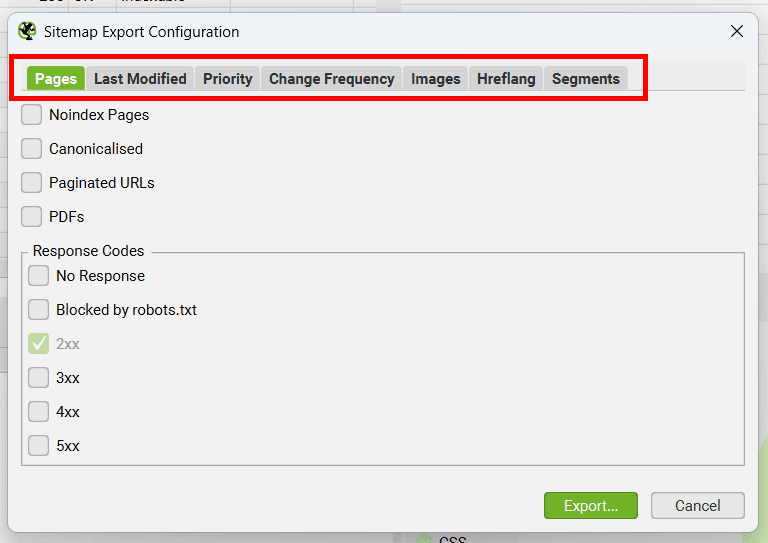
Voici les options de configuration dans chaque onglet :
« Pages » L’onglet le plus important où vous choisissez les pages à inclure : pages noindex, pages avec balises canoniques, pages de pagination, PDFs et pages selon leur code de réponse (2xx pour les pages actives, 3xx pour les redirections, 4xx pour les pages d’erreur, 5xx pour les erreurs serveur).
« Last Modified » Ajoutez la date de dernière modification avec la balise <lastmod>. Vous pouvez utiliser la date du serveur ou la définir vous-même.
« Priority » Définissez l’importance de vos pages avec la balise <priority>. Plus une page est proche de la racine du site (profondeur 0-5+), plus sa priorité peut être élevée.
« Change Frequency » Indiquez la fréquence de mise à jour de vos pages avec <changefreq>. Cette information peut être calculée automatiquement selon la date de dernière modification ou la profondeur de la page.
« Images » Choisissez quelles images inclure dans votre sitemap : toutes les images, images noindex, ou uniquement celles avec un certain nombre de liens entrants. Vous pouvez aussi spécifier des images hébergées sur des CDN.
« Hreflang » Pour les sites multilingues, ajoutez les informations de langue avec la balise hreflang.
« Visualisations » : Explorez la structure de votre site.
Screaming Frog propose plusieurs visualisations interactives qui s’ouvrent dans son navigateur intégré. Ces représentations vous permettent d’analyser efficacement la structure de votre site avec des options de zoom, de filtrage et de recherche.
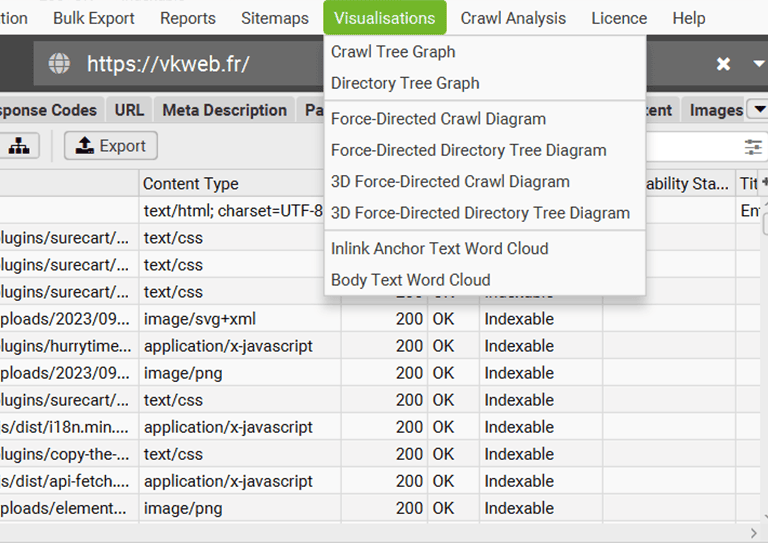
- « Crawl Tree Graph » Cet outil génère un graphique en arbre qui montre la hiérarchie des pages d’un site à partir de la page d’accueil. Il permet de visualiser comment les pages sont liées entre elles, facilitant ainsi l’identification des pages profondes ou isolées et l’évaluation de la navigation globale du site.

Cet outil génère un graphique en arbre montrant comment le site a été exploré. - Directory Tree Graph
Ce graphique, similaire au « Crawl Tree Graph », organise les URLs en fonction de la structure des dossiers du site. Cela offre une vue claire de l’organisation des fichiers et aide à repérer les sections désorganisées ou nécessitant des ajustements structurels. - « Force-Directed Crawl Diagram »
Un diagramme interactif où chaque page est représentée par un nœud et les connexions illustrent les relations entre les pages. Cet outil permet d’analyser visuellement les relations internes et d’identifier rapidement les liens problématiques ou mal configurés. - « Force-Directed Directory Tree Diagram »
Une version orientée vers les répertoires du « Force-Directed Crawl Diagram ». Les nœuds regroupent les pages par répertoires, montrant les relations et la répartition des contenus par sections ou dossiers du site. - « 3D Force-Directed Crawl Diagram »
Ce graphique en 3D est une version avancée et immersive du « Force-Directed Crawl Diagram ». Il permet d’explorer les connexions entre les pages de manière plus intuitive, offrant une visualisation claire des structures complexes de liens internes.
« 3D Force-Directed Crawl Diagram » - « 3D Force-Directed Directory Tree Diagram »
Une variante 3D du « Force-Directed Directory Tree Diagram », axée sur les répertoires et leurs relations. Cette perspective tridimensionnelle facilite l’exploration des interconnexions dans les structures de sites volumineuses ou complexes. - « Inlink Anchor Text Word Cloud »
Cet outil crée un nuage de mots basé sur les textes d’ancrage des liens internes. Les mots les plus fréquents apparaissent plus grands, offrant une vue rapide sur les termes souvent utilisés dans les ancres et les opportunités d’optimisation pour le SEO. - « Body Text Word Cloud »
Ce nuage de mots se concentre sur le contenu textuel des pages analysées, mettant en évidence les mots-clés dominants. Cela permet de mieux comprendre les thèmes principaux abordés sur le site et d’évaluer la pertinence du contenu par rapport aux mots-clés ciblés.
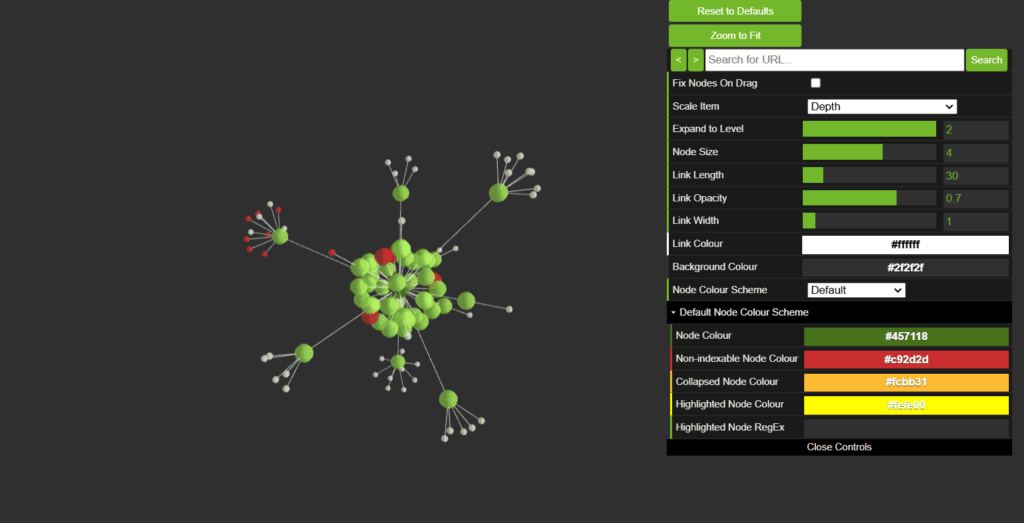
Avec ces fonctionnalités, Screaming Frog offre des outils de visualisation puissants et intuitifs pour mieux comprendre la structure d’un site et identifier les points d’amélioration en matière de SEO. Ces représentations graphiques apportent une perspective nouvelle et complémentaire pour optimiser la performance globale d’un site.
Conclusion
Screaming Frog est un outil incroyablement flexible et puissant, capable d’extraire une quantité impressionnante de données pour l’analyse SEO, à condition (oui, je sais, ce n’est pas simple !) de configurer correctement le crawling. J’espère que ce guide vous aidera à mieux comprendre et utiliser cet outil. Bien sûr, il est impossible de tout couvrir dans un seul article, mais les principales fonctionnalités devraient désormais être plus claires.
Un conseil amical : si vous débutez dans le SEO, avancez pas à pas avec Screaming Frog SEO Spider. Ne cherchez pas à tout maîtriser immédiatement, au risque de manquer des détails importants. Prenez le temps de vous familiariser avec ses fonctionnalités.
Pour approfondir vos connaissances, je vous invite à consulter nos articles sur le SEO :
- Alternatives à Screaming Frog SEO Spider
- Guide pratique pour optimiser le référencement des sites e-commerce
Si vous souhaitez un accompagnement professionnel pour booster votre SEO, nos experts sont à votre disposition avec des services SEO sur mesure.
Et ce n’est pas tout ! Découvrez dans notre catalogue d’outils IA des solutions pour créer, personnaliser et optimiser vos sites web en toute simplicité : génération de sites complets, automatisation du codage ou reproduction de designs existants. Ces outils peuvent transformer votre approche et maximiser vos résultats.
Bonne exploration et beaucoup de succès dans vos projets SEO ! 🚀
")