Avant qu’une page n’apparaisse dans les résultats de recherche, il lui reste un long chemin à parcourir. Tout d’abord, elle doit être scannée par les robots d’exploration d’un moteur de recherche (également appelé « crawl Google », le processus par lequel Google explore les pages web pour les ajouter à son index). Si le contenu est de qualité et de valeur suffisante, la page apparaît dans le SERP (abréviation de « Search Engine Results Page »). Tout cela semble simple, rapide et pratique, n’est-ce pas ?
« L’exploration web (ang. crawling) dans la terminologie SEO (référencement naturel) est l’exploration des pages du site par un robot de recherche, les indexant pour former des résultats de recherche. »
Mais comment indexer son site sur Google de manière efficace ? Le processus d’indexation lui-même, ses algorithmes et ses mécanismes restent souvent cachés. Pourtant, il existe des éléments utiles et intéressants à connaître. Dans cet article, nous allons décortiquer le processus d’indexation. Nous découvrirons ce que c’est, comment cela fonctionne et s’il est possible d’influencer la vitesse à laquelle de nouvelles pages sont ajoutées à Google.
Quelle est la différence entre Google l’Indexation et le Ranking Google
Les webmasters et les référenceurs débutants confondent souvent l’indexation avec le Ranking Google. Les deux concepts sont interdépendants, mais présentent un mode de fonctionnement différent.
- La mise en place de l’indexation du site Web est la base du travail de SEO ( référencement naturel ).
Ranking en français signifie classement. Le Ranking Google fait ainsi référence au positionnement d’un site Internet dans les pages de résultats des moteurs de recherche. Le classement est le positionnement final des sites Internet qui figurent dans les résultats de la recherche. Donc, un classement spécifique peut être attribué à une page spécifique lorsqu’elle est dans l’index, et uniquement au moment où l’utilisateur saisit certaines phrases. Cet ordre a été mis en place pour garantir que les pages les plus pertinentes apparaissent en première position dans les résultats de recherche.
Qu’est-ce que l’indexation d’un site Web ?
L’indexation est le processus par lequel un moteur de recherche recueille des informations sur le contenu de votre site. Cela prend en compte aussi bien les ajouts que les mises à jour d’une ou de plusieurs pages du site.
Comment fonctionne l’indexation Google
Le fonctionnement d’un robot de recherche Google est basé sur les mêmes principes qu’un navigateur (Browser). Le robot (le spider, web-crawler) explore les sites, évalue le contenu des pages (images, vidéos, PDF, etc.), les transfère à la base du moteur de recherche, puis suit les liens vers une autre ressource, en répétant l’algorithme d’actions appris. Le résultat de ces voyages est l’énumération des ressources Web dans un ordre strict, l’indexation de nouvelles pages et l’inclusion de plateformes inconnues dans la base de données du moteur de recherche.
Cela s’appelle un index.
À l’avenir, les données collectées pourront être utilisées de plusieurs manières différentes. Du classement des pages, au classement dans les “recherches connexes”, aux facteurs qui déterminent votre autorité de domaine, ainsi qu’à d’autres fins auxiliaires.
Le moteur de recherche ne peut indiquer que les données des pages disponibles qui ont déjà été indexées par lui. Tant que l’indexation initiale n’a pas eu lieu, elle n’existe pas pour Google. Mais dès lors que Google trouvera a un accès rapide aux informations contenues dans ses bases de données, une recherche sur plusieurs millions de pages peut prendre quelques millisecondes.
Il est à noter que même si le web-crawler a déjà «exploré» la page, cela ne garantit pas qu’elle apparaîtra instantanément dans les résultats. Certes, le robot d’exploration examine minutieusement toutes les pages, mais seules les pages avec un contenu utile et unique passent dans le SERP.
Il n’est pas possible de tricher avec le moteur de recherche, et même si c’était le cas, cela ne durerait pas longtemps. Pour reconnaître des contenus de mauvaise qualité, Google a développé ses propres outils, protégés par des brevets.
- Index E-A-T, évaluation de la Page Quality et algorithme BERT – tous ces développements vous permettent de déterminer avec précision l’utilité du contenu de la page et de reconnaître automatiquement sa qualité. Ces directives sur l’apprentissage de machines interconnectées offrent un aperçu de l’expérience de l’utilisateur.

Qu’est-ce que l’index Google
Comme nous l’avons abordé plus haut, un index est une grande base de présentation des données qui se compose de plusieurs sections clés. Nous n’avons pas besoin de nous attarder là-dessus parce que ce n’est pas très important. Permettez-nous simplement de dire que la base de données dont nous faisons mention ici contient des informations sur plusieurs millions de pages.Lors de la numérisation, les robots “ressentent” non seulement les informations textuelles de la page visibles par l’utilisateur, mais également d’autres données : les attributs du document, les informations des balises (alt, titre, description) et d’autres aspects techniques.
«L’une des dernières mises à jour majeures de Google est Mobile-First-Indexing, l’indexation mobile de tous les sites Web nouveaux et inconnus de Google, depuis le 1er juillet 2019.»
Comment un index Google est créé : toutes les étapes
Si l’on imagine la formation de l’index par étapes, elle en comprendra essentiellement quatre :
- La première étape est l’extraction de texte. À ce stade, la page est convertie et tous les éléments auxiliaires en sont “supprimés” : le texte est séparé du reste des composants, en ce compris les images, le balisage et les éléments structurels.
- La deuxième étape est la formation d’une liste des lexèmes. Le robot Googlebot forme l’ensemble sélectif. Ceci est fait afin de mettre davantage en évidence ce que l’on appelle le lexème. En linguistique, le terme «lexème» fait référence à un certain mot ou une certaine expression, qui est considéré(e) comme une unité. En fait, des lexèmes similaires sont alloués à la deuxième étape de l’indexation des pages. Les lexèmes sont collectés à partir de tous les textes (plus précisément, ils sont attribués à partir de tous les mots) qui se trouvent sur votre page.
- En troisième lieu : la commande et le traitement. À ce stade, tous les lexèmes formés sont classés par ordre alphabétique et numérotés. Cela donne à chaque lexème son propre numéro de page (indiquant la source d’origine du lexème) et un numéro d’occurrence.
- Quatrièmement : la formation d’un enregistrement d’index. Il se présente schématiquement comme suit :
Lexème/№page+№occurrence/№page+№occurrence/
Les robots d’exploration peuvent former un enregistrement plus complexe, mais sa syntaxe sera toujours basée sur le schéma ci-dessus.
Est-il possible d’accélérer l’indexation de nouvelles pages
C’est possible, mais pas de manière directe. Si une nouvelle page n’apparaît pas dans les résultats de recherche pendant une longue période, vous devez vérifier qu’elle est bien accessible aux robots d’indexation.
Pour ce faire, ouvrez le fichier système robots.txt (il est situé dans le dossier principal du site). Par exemple, pour le site vkweb.fr, le fichier robots.txt est accessible à l’adresse vkweb.fr/robots.txt. Recherchez une directive de blocage qui pourrait empêcher les robots d’accéder à votre URL. Cela peut ressembler à ceci :

La balise meta “noindex, follow” empêche l’indexation de l’URL sur Google tout en permettant aux robots d’explorer les liens présents sur la page.
Pour vérifier l’indexation d’une page sur Google, ouvrez les outils pour les webmasters. (Bien sûr, pour commencer à travailler sur Google Search Console, il faut créer un compte).
Ensuite, entrez l’url de la page et obtenez un rapport sur son indexation.
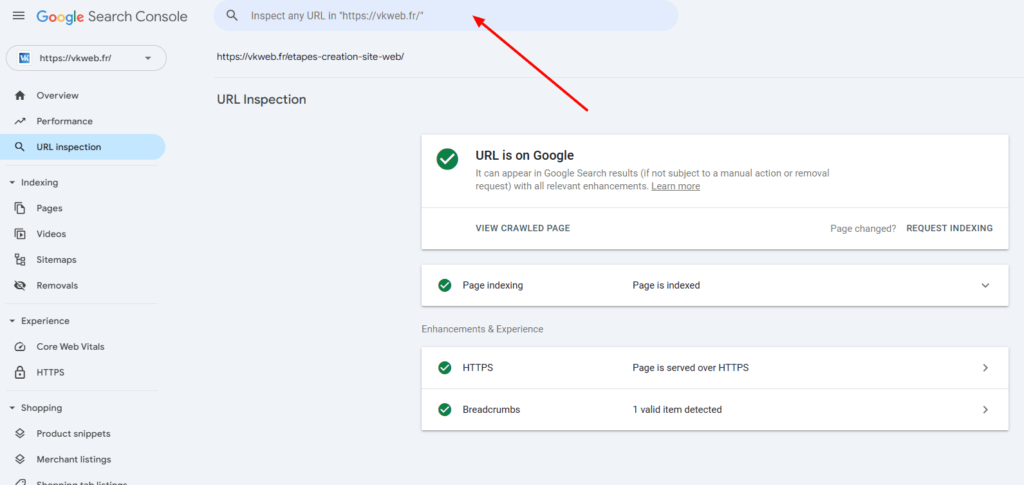
Si nécessaire, vous pouvez créer ici une nouvelle requête d’indexation (si la page n’est pas saisie dans l’index Google).
En créant une nouvelle file d’attente d’exploration, Googlebot, comme les autres robots de recherche, examine le plan du site (sitemap) et ajoute des liens de ce plan à la file d’attente. Pour améliorer l’indexation, créez un plan du site – sitemap.xml et signalez-le au moteur de recherche. Sitemap.xml est le moyen le plus simple lors de la soumission des pages de votre domaine pour l’indexation de la page de votre entreprise.
- Un budget de crawl Google, dans la terminologie SEO, est le nombre de pages d’un site qu’un robot de recherche peut explorer dans une unité de temps donnée. Parfois, un robot n’est tout simplement pas capable d’explorer toutes les pages à la fois ; vous devez donc prendre des mesures pour vous permettre d’optimiser cet indicateur.
Pour optimiser au mieux votre budget de crawl, bloquez les pages inutiles dans le fichier robots.txt et ne les incluez pas dans le fichier sitemap.xml. Seules les pages importantes et utiles doivent figurer dans le plan du site. Cela permet de le libérer des spams, des URL avec des redirections inutiles, des erreurs canoniques ou des problèmes d’exploration.
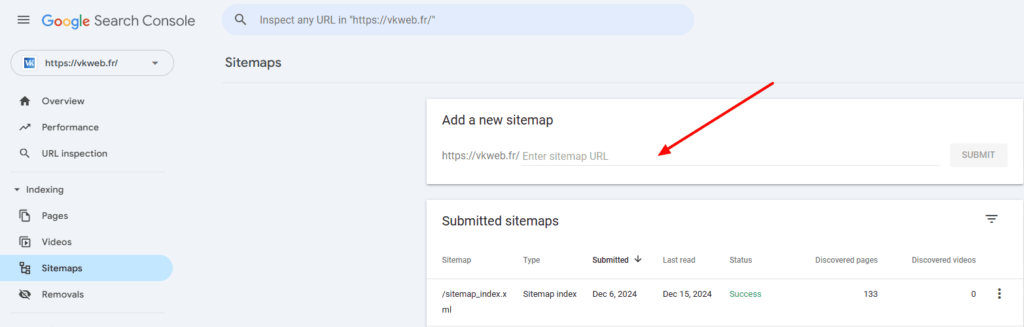
Dans la section « Sitemaps » de Google Search Console, indiquez le lien vers votre fichier sitemap.xml. Une fois soumis, ce plan sera envoyé pour vérification par Google.
Lors de l’exploration d’un site web, le fichier sitemap.xml sert de guide pour le Googlebot, indiquant précisément les pages à explorer et à indexer.
Pour que les nouvelles pages soient indexées rapidement et sans problème, il est essentiel de proposer un contenu de qualité. Tous les éléments de la page doivent être optimisés et correctement placés, y compris les balises, les images, les titres et les descriptions.
Comment retirer une page de site Web de l’indexation / la supprimer de Google
Vous souhaitez masquer une page spécifique des robots d’exploration (par exemple, des pages d’accueil techniques ou des pages contenant les termes et conditions d’utilisation, des informations confidentielles comme vos mots de passe LinkedIn, Bing etc.)? Voici trois méthodes : vous pouvez utiliser la balise robots, ajouter une directive complémentaire d’interdiction au fichier système robots.txt, ou encore utiliser les outils Google. Examinons ces trois méthodes plus en détail.
Pour fermer la page de l’indexation à l’aide de la balise meta Robots, ajoutez simplement le code suivant à l’en-tête de page ( <‘head’>):
<‘meta name=”robots” content=”noindex, follow”/’>
Maintenant, à propos de la directive d’interdiction dans robots.txt.
Ce fichier contient nos « souhaits » pour les robots de recherche, mais ils seront exécutés à leur discrétion. Pour demander aux web crawlers de ne pas explorer une page, ajoutez simplement l’instruction suivante dans le fichier robots.txt :
User-agent: Googlebot
Disallow: /catalog/ lien vers votre page
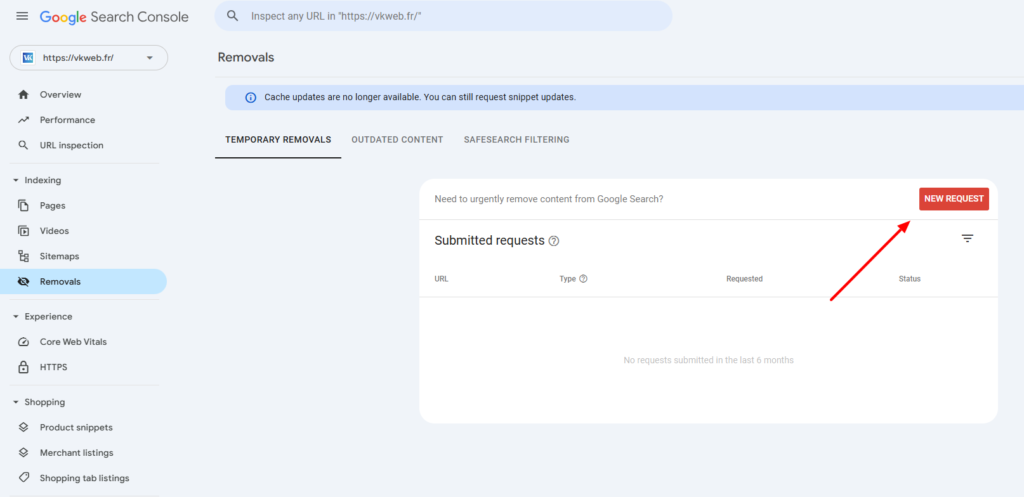
Passons aux outils pour les webmasters Google Search Console. Ouvrez l’outil de suppression d’URL. Dans le menu, sélectionnez le domaine concerné, puis l’option « Créer une demande ». Indiquez le lien à supprimer et cliquez sur « Removals ». Suivez ensuite les instructions de l’outil pour retirer l’URL des résultats de recherche. Une fois la demande soumise, les pages seront supprimées de l’index Google. Il faudra toutefois patienter quelques jours pour que le processus soit finalisé.
Comment savoir si une page est indexée ?
Il existe plusieurs façons de vérifier l’état d’une page dans l’index des moteurs de recherche. Le plus simple est de saisir un opérateur site:+url (exemple : site:vkweb.fr/creer-une-page-facebook-professionnelle/) de la page dans la barre de recherche Google. Si la page a déjà été indexée, elle apparaîtra dans les résultats de recherche. Dans le cas contraire, vous n’obtiendrez aucun résultat.
Pour ce faire, dans la zone de recherche, entrez un opérateur comme site: l’adresse de votre site.fr, par exemple: site: vkweb.fr
Dans les résultats de recherche, vous vourrez toutes les pages qui sont actuellement dans l’index Google:
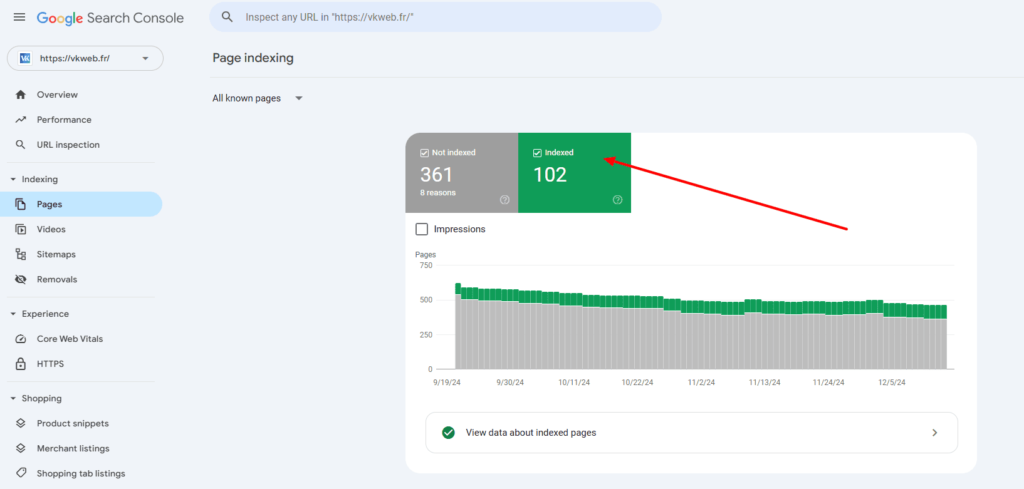
Vous pouvez également voir le nombre de pages indexées dans Google Search Console. Sélectionnez l’onglet «Coverage». Le nombre total de pages indexées sera affiché ici:
Pourquoi la page indexée peut quitter le SERP
Il existe de nombreuses raisons pour qu’une page abandonne l’index. Nous vous citons les plus courantes que nous rencontrons nous-mêmes régulièrement :
1. Le statut de la page affiche le code 301– si une redirection est configurée, une telle page ne restera pas longtemps dans les résultats de la recherche;
2. L’interdiction d’indexation est configurée dans le fichier système robots.txt;
3. Duplication de contenu;
4. Attribut canonique configuré qui mène à une autre page Web;
5. Le site a été sanctionné par Google;
6. Le statut de la page affiche les codes 400 ou 500– le Google crawler ne comptera pas du tout ces pages Web.
Conclusion
L’indexation est l’étape la plus importante de la collecte de données sur des sites Internet dans les moteurs de recherche. Sans indexation, les nouvelles pages Web n’apparaîtront jamais dans les moteurs de recherche. L’indexation ne peut être influencée qu’indirectement: toute commande ou note dans le fichier robots.txt ne sont en fait que des recommandations. C’est Google qui déterminera l’indexation.
Il convient de noter que les principaux moteurs de recherche suivent sans aucun doute ces recommandations. Si la plupart de vos pages sont indexées mais qu’on les retrouve loin dans les résultats de recherche Google (page 5 et suivantes), notre conseil est le suivant : travaillez avec diligence sur la qualité de votre contenu.
Toutes les pages seront indexées, mais les contenus inutiles et les spams ne seront jamais classés à égalité avec les plateformes de qualité dans les résultats de recherche.
Vous avez besoin d’un audit de site ou d’une évaluation de son potentiel pour attirer du trafic via les moteurs de recherche? Contactez VK Web pour des solutions efficaces !
")